处理器乱序执行基础
很精炼的介绍,听不懂可以多听几遍。
该篇笔记按一条主线来整理:先看顺序流水线为什么会浪费并行性,再看寄存器重命名如何消除伪相关,接着看发射队列如何挑选可执行的指令,最后看 ROB 如何把乱序执行重新收束成软件可见的顺序行为。
要关注的核心问题只有三个:
- 如何在保留 RAW 真依赖的前提下,消除 WAW、WAR 这类伪依赖。
- 指令重命名后,如何进入后端并等待合适的发射时机。
- 指令已经乱序执行之后,如何保证顺序提交、精确异常和出错回滚。
从静态流水线到动态流水线
先看一个最典型的动机:顺序流水线按程序顺序推进,一旦前面的指令卡住,后面即使已经就绪,也只能一起等待。
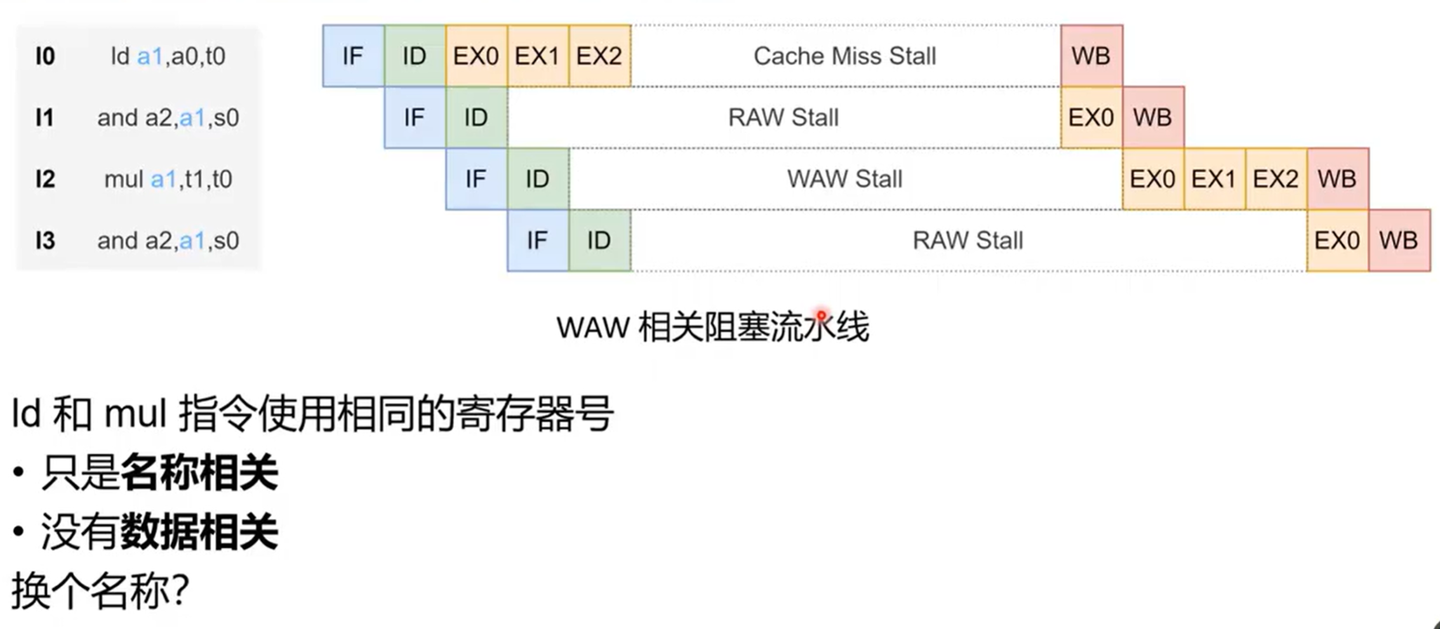
图:前面的长延迟指令会把后续原本可以并行的指令一起拖住。
mul会因为和ld写同一个寄存器而停下来,等待前面的写回完成。- 但这种停顿并不来自真实的数据依赖,而只是“写同一个名字”的名称相关。
- 如果
mul实际上不依赖ld的结果,那么它完全可以更早执行。
这就引出了动态流水线的核心想法:让已经就绪、且不受真依赖约束的指令先跑起来。
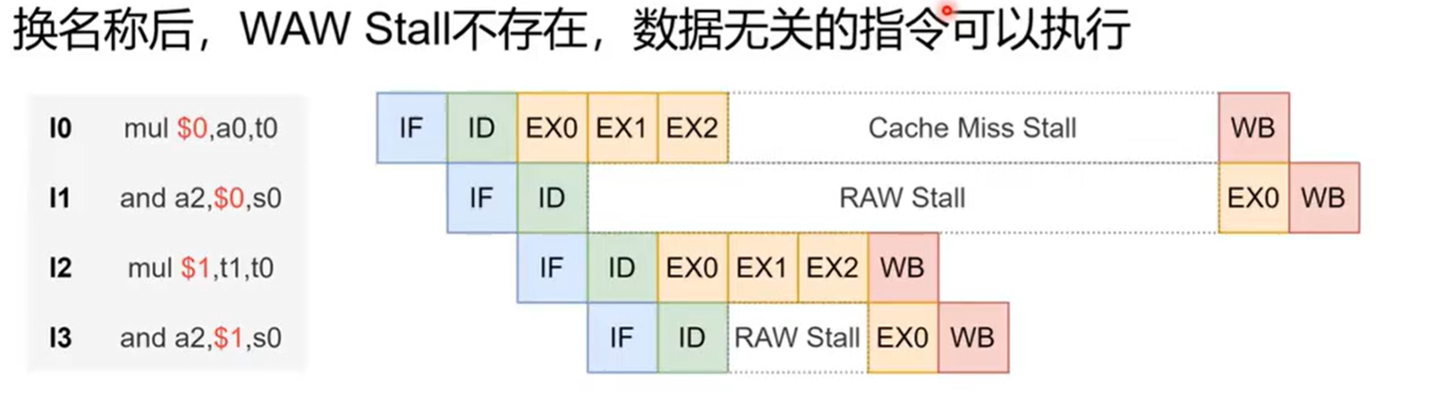
图:通过给目的寄存器重新分配物理寄存器,可以消除名称相关。
解决方法就是寄存器重命名。把发生 WAW 冲突的目的寄存器换成另一个物理寄存器,例如把 I2 的目的寄存器从 $0 换到 $1,就能消除这条伪依赖。这样一来,mul 就可以在资源允许时抢跑,去掩盖前面 ld 的延迟,同时仍然保留真正需要遵守的 RAW 依赖。顺便一提,原图里有一处笔误,I0 实际上是 ld,不是 mul。
香山后端流水线总览
下面从一个宏观的角度看一下,整个乱序处理器的布局
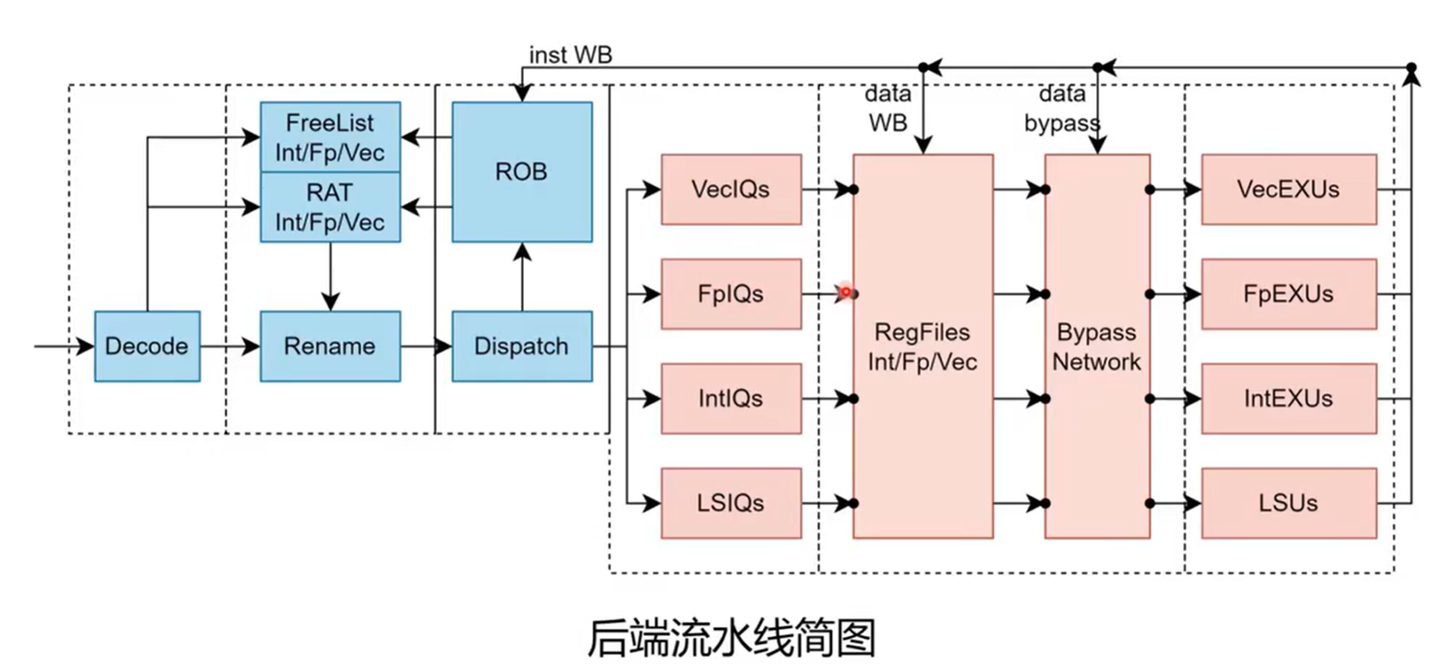
图:从译码、重命名、派发、发射到执行和提交的整体后端路径。
前端向后端送出指令,经过译码器,然后 rename 阶段进行寄存器重命名消除 WAW,WAR 冲突。随后进到 dispatch 指令派发,该单元根据不同指令计算类型进到不同的发射队列。
在发射队列中等待所需要的源操作数准备好了之后,再从发射队列里面出来,然后从寄存器和数据旁路获取到前递数据(如果有)之后,送到对应的功能单元执行。执行完成后,把结果写到 ROB、寄存器,需要 bypass 的结果写到 bypass 网络中。
寄存器重命名
重命名模块是乱序执行的入口之一,它负责把“软件看到的寄存器名字”转换成“硬件真正使用的物理寄存器编号”。
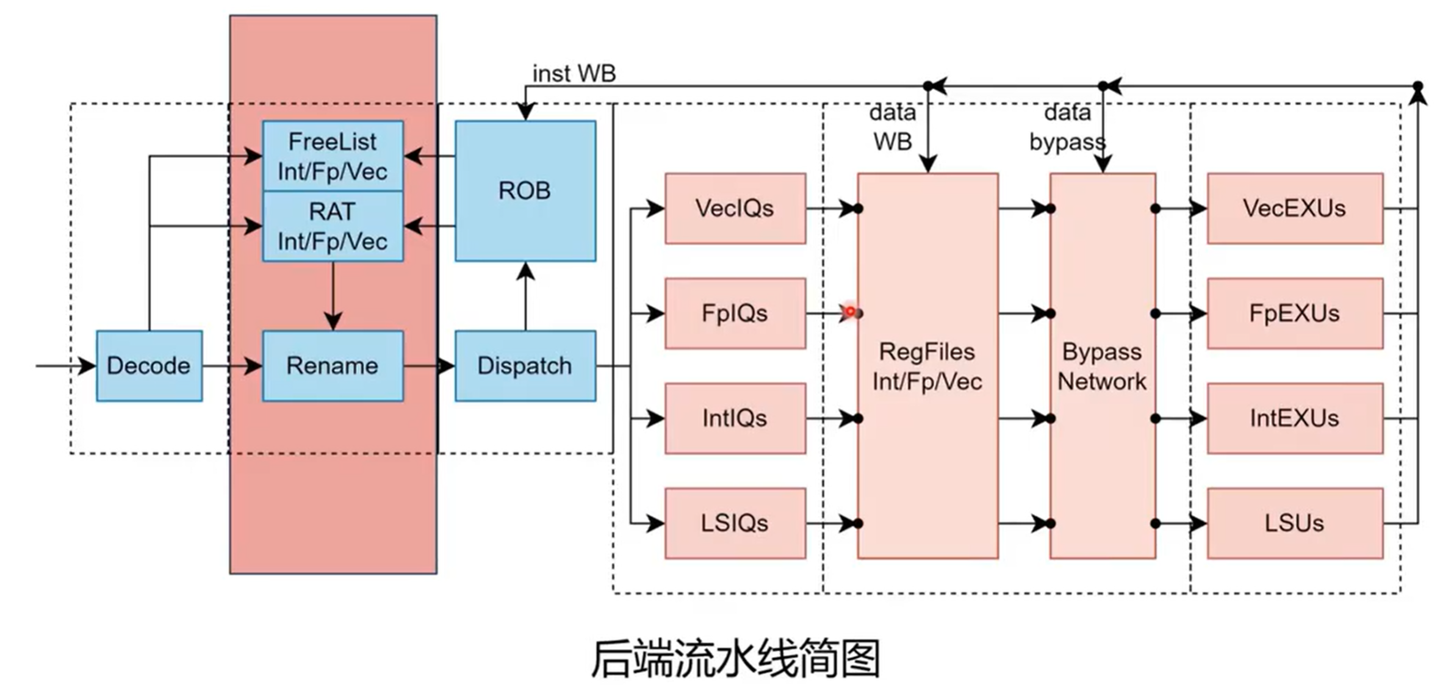
图:重命名模块位于译码之后、派发之前。
这个模块通常包含三部分:
Freelist:管理当前可分配的空闲物理寄存器。RAT(Rename Table):记录逻辑寄存器到物理寄存器的映射,通常会分为推测表和体系结构表。Rename Logic:组合逻辑本体,负责查表、分配和更新映射关系。
这里要先区分两类寄存器:
- 逻辑寄存器,也就是 ISA 定义的架构寄存器。以 RISC-V 为例,就是那 32 个通用寄存器。
- 物理寄存器,是硬件为了支持乱序和消除冲突而额外准备的寄存器资源。
重命名的目标很明确:
- 消除伪数据依赖:
WAW和WAR。 - 保留真数据依赖:
RAW。
换句话说,重命名不是为了“打乱依赖”,而是为了把真正必须保留的依赖筛出来,把只是名字重复造成的约束去掉。
Rename 的基本流程
重命名阶段通常做三件事:
- 为目的寄存器分配新的物理寄存器编号。
- 更新逻辑寄存器到物理寄存器的映射关系。
- 让消费者指令继续依赖生产者对应的物理寄存器,从而保留 RAW 关系。
一个关键细节是:先重命名源寄存器,再重命名目的寄存器。
- 源寄存器查的是旧映射,因为它要读的是当前逻辑寄存器对应的“已有值”。
- 目的寄存器分配的是新映射,因为它要写的是“即将产生的新值”。
- 目的寄存器需要从 freelist 分配空闲寄存器然后重命名,源寄存器只需要查表进行重命名
这样的好处是什么呢,其实是只保留了一对 RAW 冲突,下一对 RAW 冲突建立在新的寄存器映射上面,下面根据例子体会
重命名算法例子

图:一个简单的逻辑寄存器到物理寄存器重命名过程。
假设初始状态如下:
- 4 个体系结构寄存器:
r0到r3 - 8 个物理寄存器:
p0到p7 - 初始映射:
r0-r3分别映射到p0-p3
右上角给出的指令序列里,第 3 条指令依赖第 2 条指令的结果,因此最终必须保留这条 RAW 依赖。
先看前两条指令的重命名:
mul r1, r2, r0- 为目的寄存器
r1分配新物理寄存器p4 - 映射从
r1 -> p1改成r1 -> p4 -
重命名结果:
mul p4, p2, p0 -
add r3, r2, r0 - 为目的寄存器
r3分配新物理寄存器p5 - 重命名结果:
add p5, p2, p0
这时候常见的疑问是:r3 看起来也没和别人冲突,为什么还要重新分配一个物理寄存器,直接沿用原来的 p3 不行吗?
这里正好可以看出 WAR 冲突为什么必须靠重命名消掉。考虑下面这个场景:
如果第二条指令沿用旧映射 r3 -> p3,假如乱序调度将指令 2 放在了指令 1 之前执行,这是可以的,因为这是 WAR 冲突。就会把新值直接写进 p3。这样前面的 sub 之后再去读 p3 时,拿到的就不是旧值,而是被覆盖后的新值,结果显然错误。
如果给第二条指令分配新的映射 r3 -> p5,情况就不同了:
- 新指令写
p5 - 旧指令继续读
p3
两者彻底解耦,WAR 冲突自然消失。这也是为什么即使“看起来没冲突”,硬件仍然会给目的寄存器分配新的物理寄存器。
继续看第 3 条指令:
- 原指令:
add r3, r3, r0 - 先重命名源寄存器:此时源
r3查到的是刚刚更新后的p5,因此得到add r3, p5, p0 - 再重命名目的寄存器:为目的
r3再分配一个新物理寄存器p6 - 最终结果:
add p6, p5, p0
最终三条指令的重命名结果是:
从这个例子可以很直观地看到:
WAW和WAR已经被新的物理寄存器映射拆开了。- 第 3 条指令仍然通过
p5正确依赖第 2 条指令,RAW 被保留下来。
提交时 RAT 和 Freelist 的动作
重命名之后,指令消除了 WAW 和 WAR 依赖,可以乱序执行,经过指令分发、发射、执行之后进入可提交状态。但在执行完成之后,还要面对另一个问题:什么时候这个新映射才算“真正生效”?
这就需要区分两个表:
- 推测执行使用的
Spec RAT - 提交后才算架构状态的
Arch RAT顾名思义,推测的意思就是不一定真的发生,如果出现错误会回滚,只有到体系结构重命名表中生效,才是确定的执行状态
大致流程如下:
重命名时,Spec RAT 会先更新,因为后续所有新进入后端的指令都要看到最新的映射;但只有当指令最终提交时,这个映射才会写入 Arch RAT,变成对软件可见、可恢复的确定状态。
因此,目的寄存器在重命名时通常会保留一组信息:
提交时要做两件事:
- 更新体系结构映射:把逻辑寄存器正式指向
current phys - 回收旧物理寄存器:把
prev phys放回Freelist

图:提交时更新 Arch RAT,并回收旧的物理寄存器。
以 mul p4, p2, p0 为例,若 prev = p1、current = p4,那么提交时会发生:
r1 -> p1更新为r1 -> p4- 旧物理寄存器
p1被回收到Freelist
这也是为什么推测表和体系结构表在大多数时刻并不完全相同。Spec RAT 总是走在前面,因为它服务于后续的乱序调度;Arch RAT 会慢一步,因为它只在 commit 时更新。

图:
Arch RAT、Spec RAT和Freelist在不同阶段的关系。
图中:
- 蓝色表示
Arch RAT - 红色表示
Spec RAT - 绿色表示
Freelist
逻辑寄存器数量固定,因此 Arch RAT 项数也是固定的;真正动态变化的是推测映射和空闲物理寄存器的分配回收。

图:随着指令重命名和提交推进,三者状态会不断变化。
发射队列
重命名解决的是“依赖关系怎么表示”的问题,发射队列解决的则是“哪条指令现在可以执行”的问题。
指令经过派发进入发射队列之后,就从顺序流进入了真正的乱序调度阶段。发射队列会暂存这些指令,等待源操作数和执行资源准备好,再把它们送到对应功能单元。
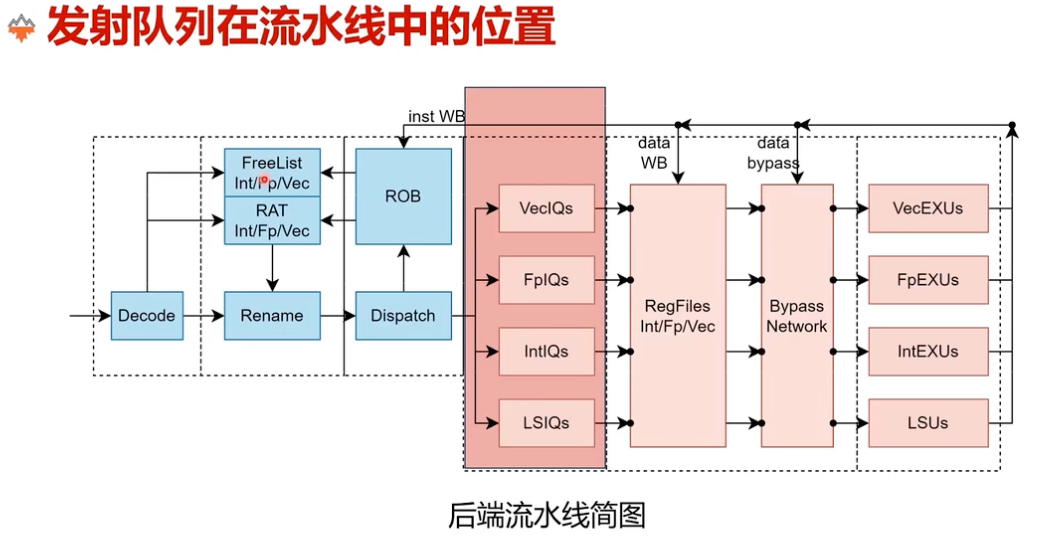
图:发射队列位于派发与执行单元之间,是乱序调度的核心结构之一。
发射队列需要完成三件事:
- 存储等待执行的指令信息 -> 存储哪些信息?
- 接收操作数就绪的广播,唤醒依赖该结果的指令 -> 何时修改操作数为就绪?
- 在所有已就绪指令中做仲裁,选择谁先发射 -> 依照什么仲裁?
发射队列的组织方式
按组织形式来看,发射队列大致有三种:
- 集中式发射队列:所有类型指令进入同一个队列,容量利用率高。
- 分布式发射队列:按整数、浮点、向量等类型拆开,单队列规模更小,更容易做时序。
- 半集中式发射队列:在容量利用率和时序压力之间折中。
集中式的优点是弹性大,不容易因为某类指令突然变多而浪费其他队列容量;缺点则是规模一大,唤醒和选择逻辑都会变重。分布式则正好相反,速度更容易做上去,但不同类型之间会出现容量不均衡的问题。
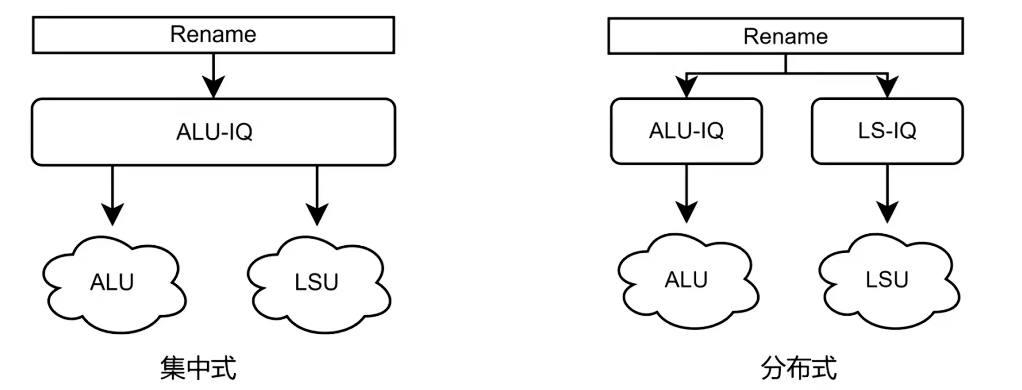
图:集中式、分布式和折中方案的示意对比。
**按是否直接保存操作数数据**来看,发射队列分为两种
- 数据捕获式发射队列:在发射前就读寄存器,队列里不仅保存 tag,还要保存被唤醒后的最新数据。
- 非数据捕获式发射队列:队列里主要保存 tag 和状态,真正发射后再去读寄存器堆。
现在高性能处理器更常见的是后者,因为如果在 IQ 里直接保存大量数据,面积和功耗都会明显上升,尤其是面对 64 位数据、浮点数据甚至向量数据时更是如此。
按照发射队列和寄存器堆的相对位置来看:
issue前读寄存器,通常意味着 IQ 需要保留最新数据,更接近数据捕获式设计。issue后读寄存器,通常可以采用非数据捕获式设计,减轻 IQ 的存储压力。
发射队列里保存什么
发射队列至少要保存下面这些信息:
valid:这一项里是否真的有有效指令psrc[n]:源物理寄存器编号type[n]:源操作数类型,例如整数、浮点、向量ready[n]:对应源操作数是否已经就绪payload:调度后续还会用到的信息,例如操作码、目的寄存器等

图:IQ 项通常同时保存 tag、ready 位和必要的 payload。
唤醒与发射条件
当某条指令执行完成后,结果会通过写回路径或旁路网络广播出来。发射队列需要监听这些广播,并把等待该结果的指令唤醒。
用于唤醒的信息一般包括:
validtypepdest
发射队列内部会拿广播出来的目的寄存器编号,与每个队列项的源寄存器编号做比较。伪代码可以写成:
一旦某条指令的所有源操作数都 ready,它就进入可发射集合。以双源操作数指令为例:
队列越大,唤醒时要比较的项就越多,电路开销也越大。这也是很多处理器把大 IQ 拆成多个分布式小 IQ 的重要原因之一。代价则是:如果某一类功能单元在某段时间特别繁忙,就可能局部拥塞。
就绪指令如何仲裁
如果同一周期有多条指令都 ready,就需要仲裁策略决定谁先发射。报告里提到了几种常见方法:
- 最老优先:性能通常最好,但需要维护年龄信息。
- 特定指令优先:例如优先执行分支,尽早给出跳转结果。
- 基于位置的近似随机选择:实现简单,但效果通常不如最老优先稳定。
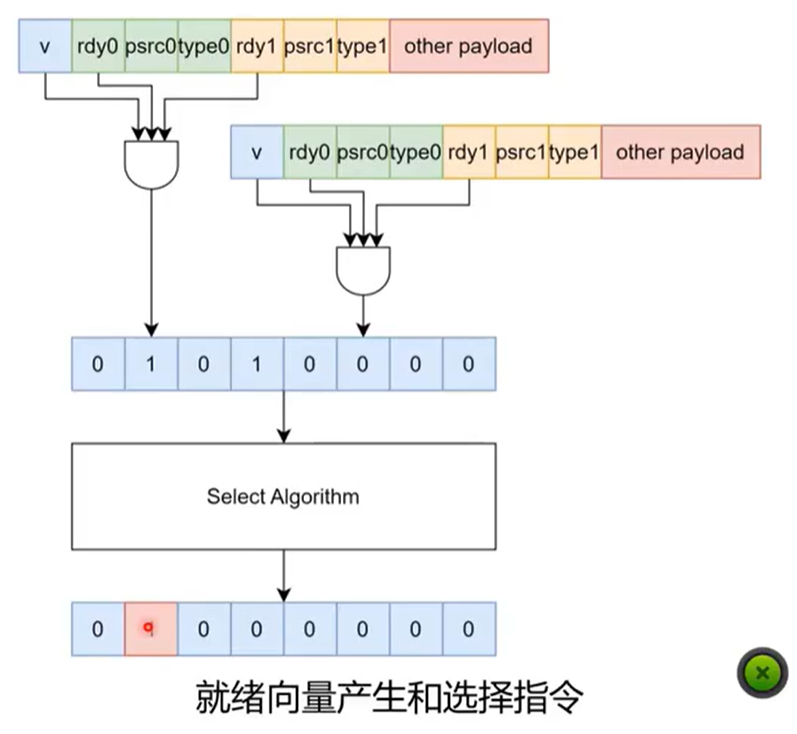
图:不同仲裁策略会影响性能、复杂度和公平性。
其他常见机制
除了基本的唤醒和选择,发射队列通常还会配合几类优化机制:
- 提前唤醒
对于执行周期固定且不会被阻塞的指令,调度器不一定要等它真正写回后再去唤醒消费者。只要指令被发射出去,硬件就已经知道它大约在第几个周期会在旁路网络上产生结果,因此可以提前广播 tag,让后继指令更早进入 ready 状态,实现背靠背执行。
- 推测发射与回滚
对于 load 这类执行延迟不完全确定的指令,也可以尝试类似的提前唤醒。但这时结果带有推测性,一旦估计失败,就必须让后续受影响的指令回滚。
- 重发
某些指令可能已经从发射队列里发出去了,但后面因为执行资源冲突等原因失败。相比重新从前端走一整遍流程,更常见的做法是让发射队列或专门的重发队列承担这部分 replay 工作,以减少额外开销。
乱序调度与重排序
到这里,指令已经可以乱序执行了。但从软件视角看,处理器仍然必须像“按程序顺序执行”一样可靠。这个“把乱序执行重新约束成顺序可见行为”的结构,就是 ROB。
指令在 rename 时就会在 ROB 中分配一项。由于这时它们还没开始真正乱序执行,因此 ROB 中的排列顺序天然就是程序顺序。后面无论执行和写回怎么乱序,最终只要严格按照 ROB 顺序提交,就能重新建立顺序语义。
精确异常
精确异常是理解 ROB 价值的一个最好入口。
在顺序处理器里,异常发生后回到正确位置继续执行,看起来是很自然的事情;但在乱序处理器里,后面的指令可能已经先一步执行完成了。如果没有额外机制,异常现场就很容易被污染。
精确异常要求:以发生异常的那条指令为界,处理器对外可见的状态必须满足下面三个条件:
- 之前的指令都已经生效
- 之后的指令都还没有生效
- 当前这条异常指令停在出错的位置
也就是说,乱序执行里“执行完成”和“真正对外生效”是两回事。前者可以乱序,后者必须受控。
看一个例子:
DIV R1, R2, R3 ; (1) 长延时指令,假设会除零异常
ADD R4, R5, R6 ; (2) 短延时指令,与 DIV 无依赖
ST R4, [0x100] ; (3) Store 指令,写内存
如果单纯允许乱序执行,就会出现下面的情况:
DIV还在执行,迟迟没有结果。ADD和ST因为不依赖DIV,已经先执行完了。R4的新值已经产生,甚至内存0x100也可能已经被改掉。- 这时
DIV才报告除零异常。
问题就来了:既然异常点在第一条指令,那么后面两条指令的效果本来都不该对外可见。
现代处理器的解决办法是把“执行”和“提交”分开:乱序执行,顺序提交
- 执行可以乱序进行
- 状态更新是临时的: 它们算出的结果不能直接写入最终的架构寄存器 (ARF) 或内存,而是写到重命名寄存器 或 ROB 中。
- 提交是顺序的: ROB 像一个 FIFO 队列,严格按程序顺序排列。
因此,ROB 的作用不是阻止乱序执行,而是把这些提前算出来的结果“暂存起来”,等轮到它们按顺序退休时再正式生效。
异常处理流程也就变成了:
DIV检测到异常,但先只是在 ROB 项里打上异常标记。- 这条指令继续按程序顺序留在 ROB 里等待轮到自己。
- 当它来到 ROB 头部时,处理器看到这是一条带异常标记的最老指令。
- 因为它已经是头部,说明前面的指令都已经提交完了。
- 这时触发异常处理,同时冲刷掉它后面的所有年轻指令。
- 那些虽然执行过、但还没提交的结果都会被丢弃,从而恢复出一个精确的异常现场。
这就是为什么乱序处理器仍然可以给软件提供“之前都做了,之后都没做”的顺序视图。
重排序缓冲(Reorder Buffer, ROB)
理解了精确异常之后,再看 ROB 的职责就会顺很多。
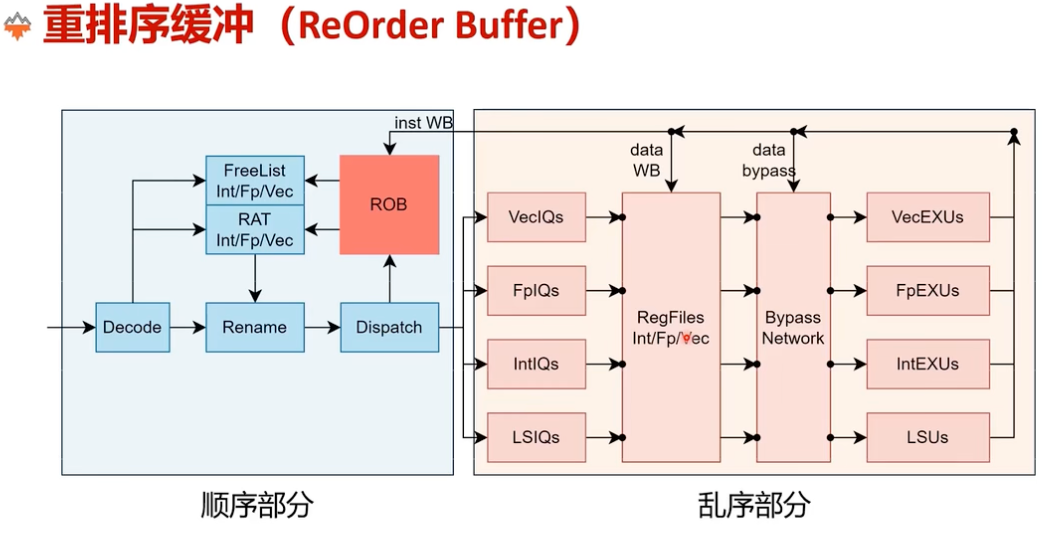
图:ROB 位于乱序后端的关键收束点,负责顺序提交和恢复。
对软件来说,看不到 CPU 内部是顺序还是乱序,它只会观察到“指令按程序顺序生效”。ROB 的核心职责就是保证这一点。整个过程可以概括为:
因此 ROB 至少承担三个功能:
- 维持指令的程序顺序
- 为推测执行提供恢复和回滚机制
- 支持精确异常
ROB 的基本形态
ROB 最常见的实现方式就是 FIFO。

图:ROB 通常按环形 FIFO 实现,
EnqPtr指向新分配位置,DeqPtr指向最老待提交项。
新指令在分配时从 EnqPtr 进入,最老的已完成指令从 DeqPtr 处提交。这种结构天然适合维护程序顺序。
一个很容易让人误解的点是:cpu 是没办法感知存储系统的行为,store 虽然可能很早就算出了地址和数据,但它对内存系统的最终修改通常也要等到提交之后才真正对外生效,否则一旦前面发生异常或回滚,内存状态就没法恢复了。
ROB 如何处理异常
异常一般要等到提交时再真正处理,而不是“谁先发现谁立刻处理”。原因很简单:只有当一条异常指令已经成为 ROB 头部时,处理器才能确定它之前的指令都已经提交、之后的指令都还没提交,从而满足精确异常的要求。
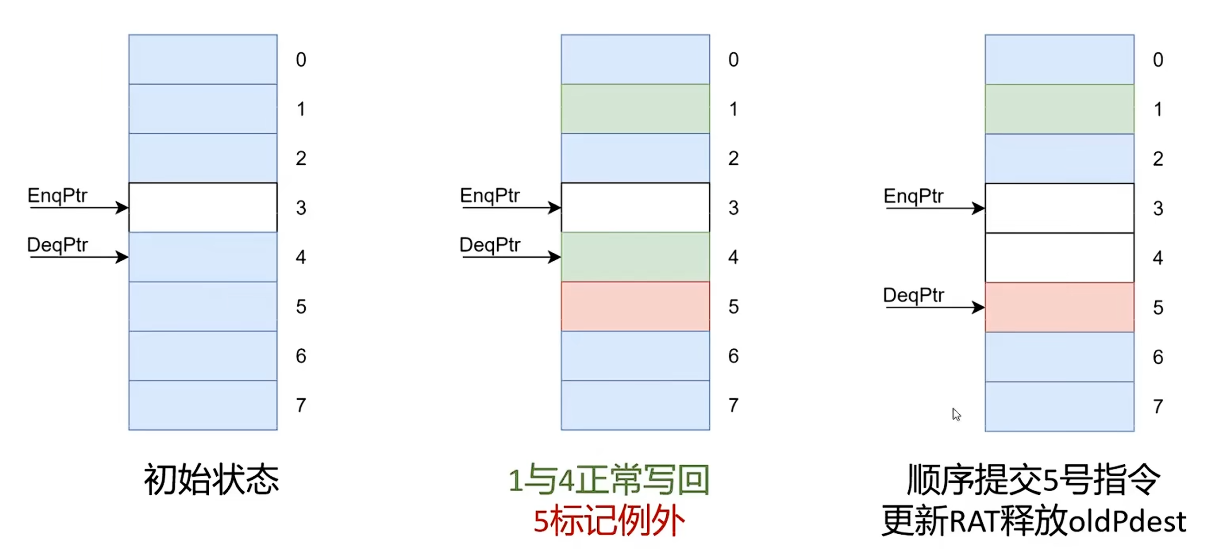
图:即便年轻指令已经写回,只要尚未提交,仍然可以在异常时丢弃。
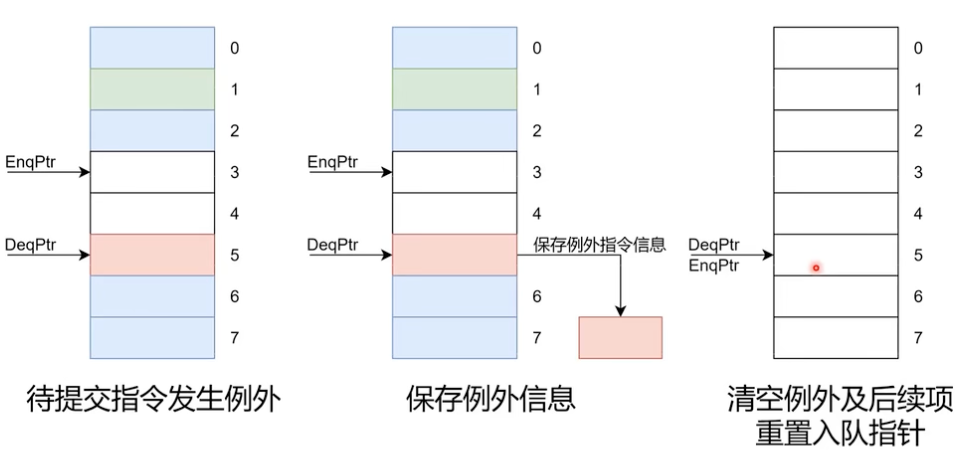
图:异常到达 ROB 头部后,后续年轻指令会被统一冲刷。
因此,异常处理的核心原则是:
- 异常标记可以提前产生
- 异常处理必须在合适的提交点发生
- 异常之后的所有年轻指令都要被 flush
ROB 如何处理误预测
分支误预测和异常有一个重要区别:误预测一旦被发现,通常就会尽快处理,不需要等它一路排队到 commit 才动手。
原因在于分支误预测本质上是“控制流走错了”,处理器已经知道哪一段后续指令是不该存在的,因此可以直接冲刷掉误预测分支之后的年轻指令,尽快回到正确路径。
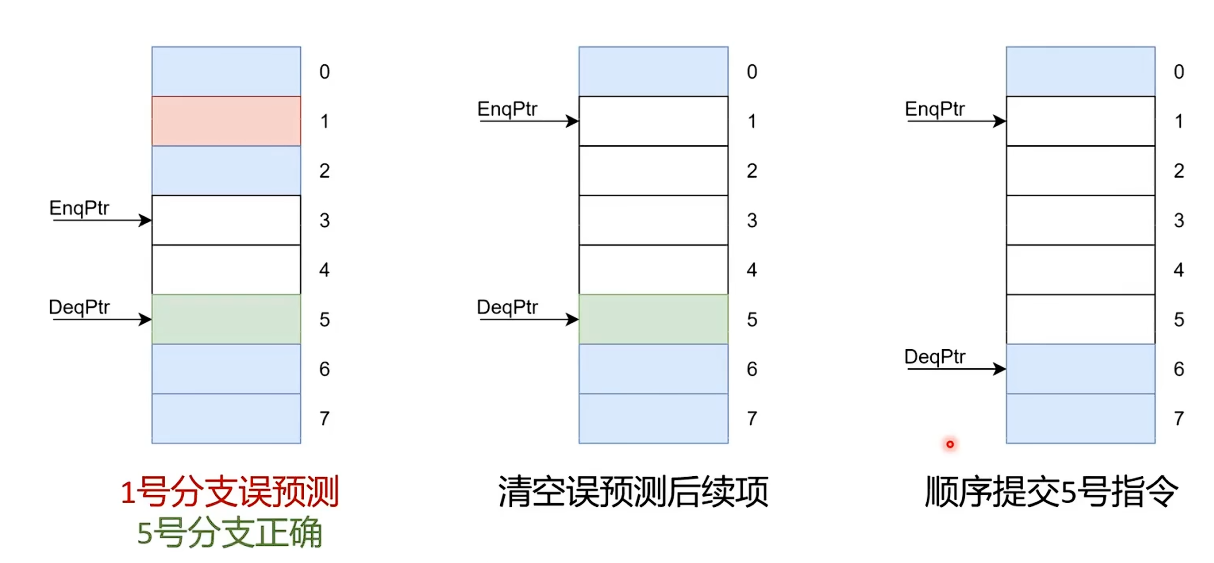
图:误预测通常在发现时立即处理,只保留分支之前的正确状态。
Flush 不只是清空 ROB
ROB 内部完成 flush 之后,还需要把这件事广播给外部结构。原因是乱序后端之外,前面还有顺序阶段的流水线。
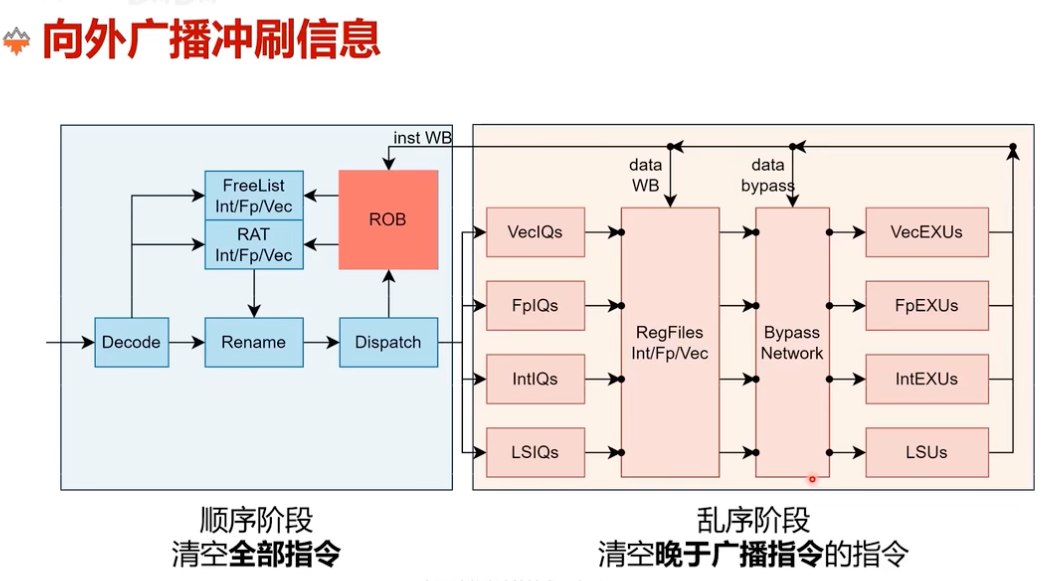
图:flush 需要同时作用于前端顺序阶段和后端乱序阶段。
可以这样理解:
- 对于前端和顺序阶段来说,它们拿到的指令一定都比当前 ROB 里的指令更“年轻”,因此通常需要整段清空。
- 对于乱序后端来说,则只需要清空晚于触发 flush 的那条指令之后的部分。
Flush 时重命名表怎么办
一旦 flush 发生,重命名表也必须恢复到正确状态。这里正好能看出为什么硬件要同时维护 Arch RAT 和 Spec RAT。
最直接的做法是:
- 把
Arch RAT复制给Spec RAT
这样至少能立刻回到一个已提交、一定正确的映射状态。
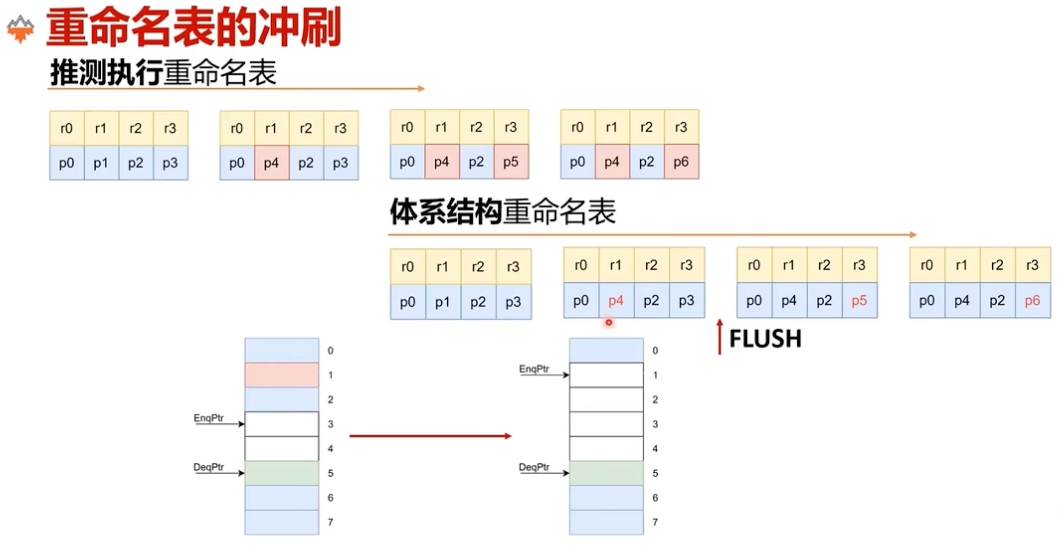
图:发生 flush 前,
Spec RAT往往已经领先于Arch RAT。
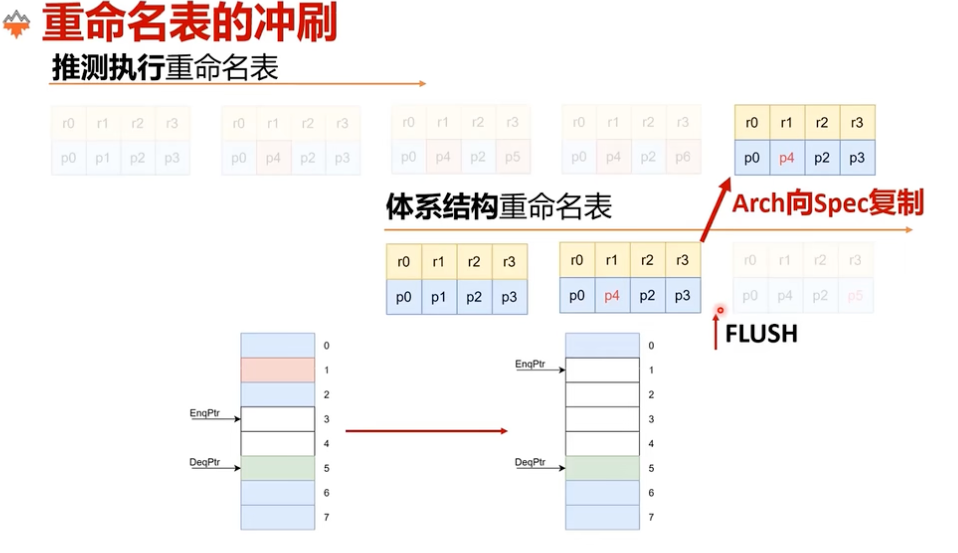
图:最直接的恢复方式是先把
Arch RAT覆盖回Spec RAT。
但这还不够。因为如果只是误预测,ROB 里往往还有一部分“仍然有效、只是尚未提交”的中间状态。简单地把 Arch RAT 复制过去,会把这些合法映射也一起抹掉。
所以还需要 walk 机制,把 ROB 中仍然有效的那部分映射重新恢复到 Spec RAT。常见思路有两种:
redo:先把 rename table flush 成Arch RAT,再顺着有效 ROB 项重新走一遍映射undo:不整体 flush,而是从当前状态开始,把无效映射一步步撤回去
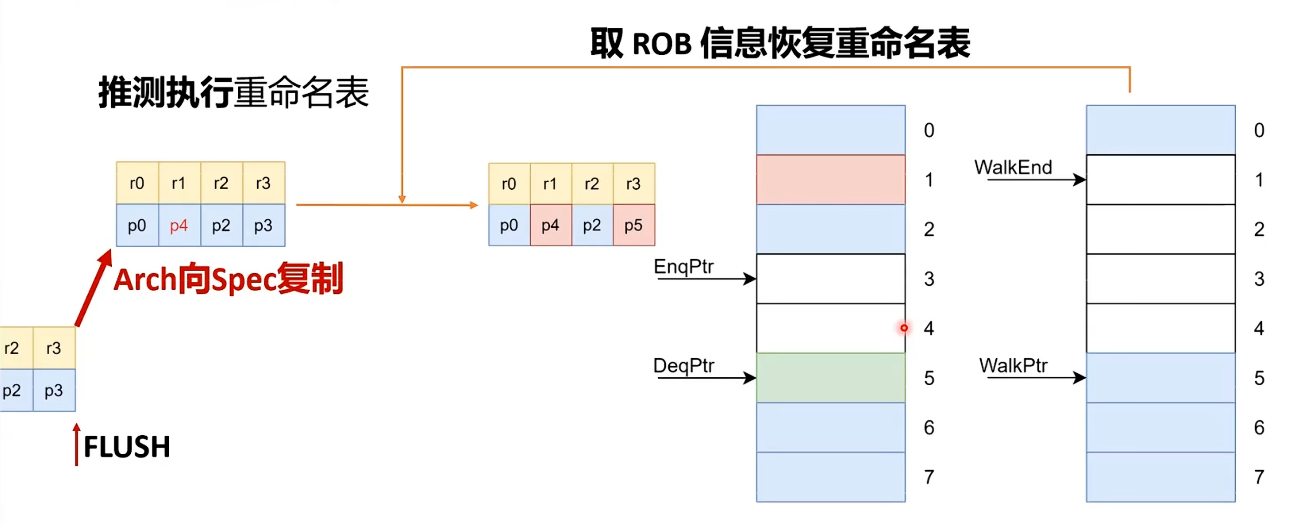
图:通过 walk 机制,可以只恢复仍然有效的那部分推测映射。
ROB 的存储优化
ROB 很大、很关键,因此也必须尽量瘦身。基本思路是:只在 ROB 里保存“提交和恢复必须要用到的信息”,其余 payload 尽量下沉到别的结构里,减少存储压力。

图:ROB 项越精简,面积和访问开销越容易控制。

图:常见优化方向是把不参与提交关键路径的信息移出 ROB。
小结
可以把乱序后端压缩成一句话来理解:
- 重命名负责“把伪依赖拆开”
- 发射队列负责“在正确的时间挑出可执行指令”
- ROB 负责“把乱序执行重新收束成顺序可见的结果”
乱序执行并不是简单地“让指令随便乱跑”,而是在硬件内部尽量挖掘并行性,同时用一整套机制严格守住正确性边界。把这三个结构连起来看,整条逻辑就会清楚很多。