RVV概念与intrinsic入门
RISC-V的Vector扩展、架构介绍、intrinsic实战、开发环境配置
开发环境
参考:https://www.cnblogs.com/sureZ-learning/p/18822215
环境配置
需要安装riscv-gnu-toolchain和qemu
1 | # riscv-gnu-toolchain的安装 |
qemu没有预编译好的版本,需要自己手动编译,为了方便,这里我们选择qemu-user模式。
1 | $ sudo apt-get install -y build-essential pkg-config libglib2.0-dev zlib1g-dev libpixman-1-dev autoconf automake libtool bison flex texinfo gcc g++ git |
编译:
使用如下命令
1 | riscv64-unknown-linux-gnu-gcc -march=rv64imafdcv -mabi=lp64d *.c -o vadd_example.elf -lm -static -O2 -g |
其中,-march=rv64imafdcv 中的v表示支持RVV
运行:
1 | /root/qemu/bin/qemu-riscv64 -cpu rv64,g=true,c=true,v=true,vlen=128,elen=64,vext_spec=v1.0 ./vadd_example.elf |
学习资料合集
RVV指令集
手册:RISC-V “V” Vector Extension Version
分享会介绍:https://www.bilibili.com/video/BV1U18jzDEuW/?vd_source=7a39dbfc457222c1894595f42f7958fd
RVV专栏博客:https://www.cnblogs.com/sureZ-learning/category/2453794.html
简短但清晰的介绍:https://fprox.substack.com/p/risc-v-vector-in-a-nutshell
快速体验RVV:https://youtu.be/Ozj_xU0rSyY?si=_45RpCPw3JheZMnm
观后感:
- RVV的意义:SIMD允许在一条指令中,对多个数据执行相同的操作
- 类比一次烤一个饼干,一次用大托盘烤几十个饼干(矢量处理);固定长度的vector register类似于固定大小的烤盘
- x86使用固定长度,随着时间推移,逐渐增加了更大的版本(1997:MMX 64bits,1999:SSE 128bits,2008:AVX 256 bits,2013:AVX 512 bits);这样有一个问题,为了向后兼容,后面的设计也会涵盖前面所有的设计,这会使得硬件相当复杂;而RV使用长度不固定的寄存器,也就是我们可以调整到任何尺寸的托盘
RVV intrinsic编程
- RVV intrinsic api查询:https://dzaima.github.io/intrinsics-viewer/#riscv
- RVV intrinsic文档:https://github.com/riscv-non-isa/rvv-intrinsic-doc
1. RVV常用缩略词
以下表格参考自:https://www.cnblogs.com/sureZ-learning/p/18822201
| 单词缩写 | 全称 | 含义 | 约束 |
|---|---|---|---|
| VLEN | Vector Length in bits | 向量寄存器长度,单位bits | VLEN≥ELEN;VLEN必须是2的幂,且VLEN <= 65536(即2^16^) |
| ELEN | Element Length | 最大元素宽度,单位bits,常见的ELEN=32 和 ELEN=64,即最大元素宽度就是XLEN值 | ELEN >= 8,且ELEN是2的幂 |
| SEW | Selected Element Width | 被选中的元素位宽,可以取8/16/32/64 | |
| EEW | Effective Element Width | 与SEW类似,有效的元素位宽,用于向量操作数。对于加宽指令,目的数据元素的位宽会加宽一倍 | |
| LMUL | Vector Length Multiplier | 寄存器组乘系数,表示一个寄存器组由多少个向量寄存器组成 | ELEN * EMUL >= SEW(你选的寄存器组合至少能够放下一个 SEW 大小的元素) |
| EMUL | Effective Element Width | 与LMUL类似,表示有效寄存器组乘系数,对于加宽指令,目的寄存器组乘系数会加宽一倍 | |
| AVL | Application Vector Length | 应用程序向量长度,指的是应用程序希望处理的数据元素总数 | |
| VL | Vector Length | 向量长度,vl(Vector Length)是一个关键的控制寄存器,RVV并不能设置vl寄存器的,而是将AVL参数传递给vsetvl指令来设置正确的vl值 |
|
| VLMAX | Vector MAX Length | 表示VL向量长度的最大值;VLMAX = LMUL*VLEN/SEW |
注意
VLEN在芯片设计好之后就是一个确定的值了,如何获取VLEN的值?- RVV有一个
vlenb寄存器,此寄存器存的是VLEN/8的值,读取该寄存器值再乘8就得到VLEN
- RVV有一个
未来V扩展可能允许使用多个向量寄存器来保存一个元素,
ELEN>VLEN,但当前版本不支持这么做SEWEEWLMULEMUL这四个参数有如下关系:EEW/EMUL = SEW/LMUL- 一般指令,
EEW=SEW且EMUL=LMUL - 加宽指令,对于源操作数:
EEW=SEW且EMUL=LMUL, 对于目的操作数:EEW=2 *SEW且EMUL= 2 *LMUL - 缩减指令,对于源操作数:
EEW=2 *SEW且EMUL= 2 *LMUL,对于目的操作数:EEW=SEW且EMUL=LMUL
- 一般指令,
例子:加宽指令
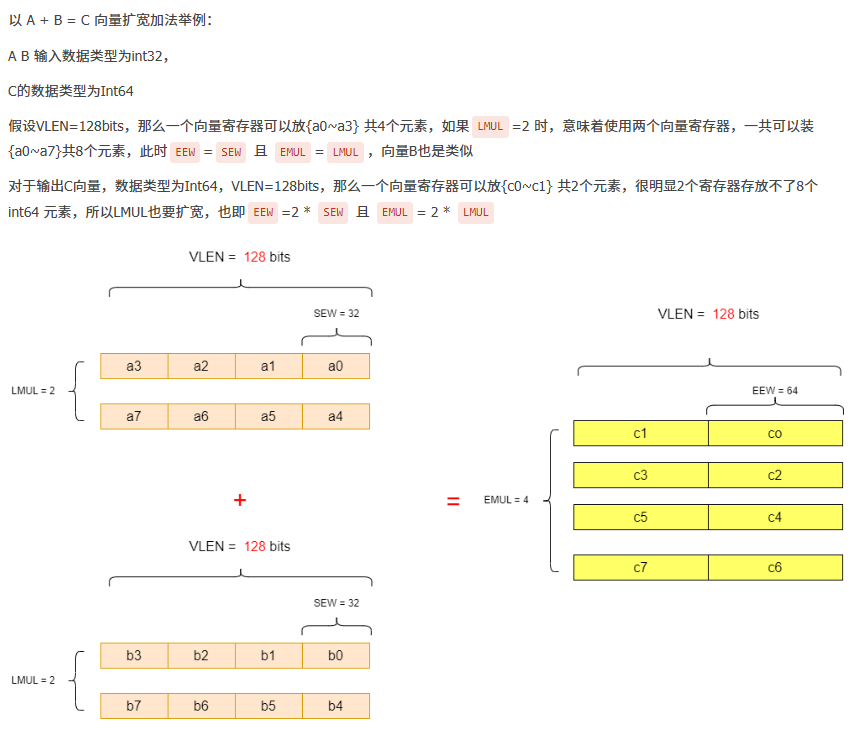
2. RVV编程模型
2.1RVV状态寄存器
2.1.1 misa.v字段
如果硬件支持V扩展指令,misa寄存器的V字段要置1,如果misa.v=0,说明硬件不支持
查表可得misa.v字段位于第21位

如何验证:在M态下读misa寄存器,可以进入gdb键入info reg misa
2.1.2 mstatus[10:9]
mstatus寄存器中的向量上下文状态域(Vector Status, VS)位于mstatus[10:9]。这个VS域可写,指示当前上下文 1)是否使用了V扩展指令集 2)向量寄存器的状态
mstatus[10:9] |
VS Meaning | 作用 |
|---|---|---|
| 0 | Off | 表示向量指令集未被启用,尝试执行任何向量指令或访问向量CSR(Control and Status Registers)将导致非法指令异常。 |
| 1 | Initial | 表示向量指令集处于初始状态,这意味着虽然尚未执行任何会改变向量状态的指令,但是可以开始执行这些指令。 |
| 2 | Clean | 表示向量指令集已经被使用过,但目前没有未保存的变化。如果执行了任何更改向量状态的指令,VS会被自动设置为Dirty。 |
| 3 | Dirty | 表示向量指令集已经被使用,并且存在未保存的变化。在这种状态下,必须保存向量寄存器内容才能安全地切换上下文。 |
这里涉及到一个状态的转移:
- 在VS=Initial 或 Clean状态,执行任何向量指令(包括访问向量CSR寄存器)将会将VS状态置为VS=Dirty状态
- 当VS=Dirty时,这通常意味着需要保存向量寄存器的内容,以避免在上下文切换过程中丢失数据。一旦向量状态被正确保存,VS域可以被清零(软件手动清0),以便其他进程可以安全地使用向量资源。正确保存后就又回到了Clean的状态。
- 注意当处于VS=off时使用向量指令,会触发指令异常
2.1.3 sstatus 和 vsstatus
sstatus寄存器中的向量上下文状态域位于sstatus[10:9],这个寄存器是mstatus寄存器VS域的映射,作用与mstatus寄存器VS域相同- 在存在Hypervisor扩展的情况下,还有一个类似的
vsstatus寄存器,其中也包含了一个VS字段,用于管理第二级虚拟化的向量状态。
2.2 RVV数据寄存器
32个向量寄存器(v0-v31),每个寄存器的宽度固定,宽度为VLEN bits
我们不是说RVV可以处理变长的数据吗,为什么每个寄存器的宽度又是固定的?
向量寄存器的数量和 VLEN 在芯片设计时就确定了,这是物理资源,不能在运行时改变。
变长不是指硬件寄存器的长度变,而是指:1)处理的数据长度是“逻辑上的可变” 2)支持不同的 SEW
假设:
VLEN = 128- 你想处理 13 个
int16_t元素(SEW=16)此时:
- 一个寄存器能放下
128 / 16 = 8个元素- 但你只设置
vl = 13(通过vsetvl设置)- 编译器和指令会自动帮你分两轮处理(前 8 个和后 5 个)
你不需要知道实际有多少个寄存器,你只写一次循环,RVV 自动处理长度不对齐问题。
这就是“VLA 向量长度不可知编程模型”的魅力:
程序员只写逻辑处理逻辑个数,底层硬件决定怎么执行。
2.3 RVV CSR寄存器
7个 unprivileged CSRs (vstart, vxsat, vxrm, vcsr, vtype, vl, vlenb) 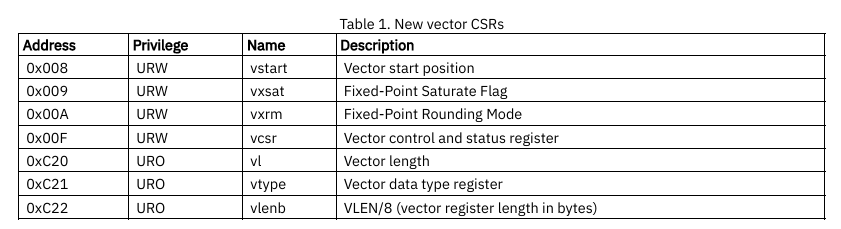
整体的描述如下:
| 寄存器名字 | 寄存器描述 | 寄存器的位域 | 备注 |
|---|---|---|---|
| vstart | 用来指示第一个参与运算的元素索引 | ||
| vxsat | 用来表示向量定点饱和标志 | 目前只用了一位,vxsat[0]:用于指示定点指令是否做饱和处理;其他XLEN-1位为0(vxsat[XLEN-1:1]为0) | |
| vxrm | 用来表示向量定点数舍入模式 |  |
|
| vcsr | 向量状态控制寄存器,目前包含vxsat与vxrm两个寄存器的镜像 |
 |
|
| vl | 向量长度寄存器,用来记录在向量寄存器中处理的元素的数量 | 只能被vsetvl指令或者fault-only-first指令更新 |
|
| vtype | 向量元素类型寄存器,用来描述向量寄存器数据元素类型 | 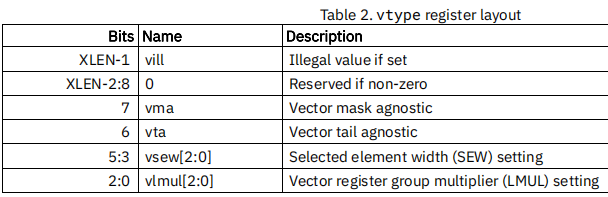 |
只能使用vsetvl指令来动态配置vtype寄存器;vtype寄存器位宽与架构位宽一致 |
| vlenb | 向量寄存器长度,用来指定一个向量寄存器有多少个字节 | vsetvl指令需要用到vlenb寄存器,用来计算vl 和 vtype |
具体描述:
vlenb
如上表格所述
vl
如上表格所述
vstart
- 一般情况下,
vstart寄存器只能由硬件执行向量指令时写入,软件不需要管。举例:当硬件执行向量指令时遇到中断或异常,硬件可以将已经处理的元素索引写入vstart寄存器,等中断或异常处理完成后,将从vstart开始恢复处理 - 所有vector指令都是从
vstart中给定的元素索引开始执行,并在执行结束时将vstart CSR重置为零。另外目的寄存器的0-vstart元素采取不打扰策略。 - 所有向量指令,包括vset{i}vl{i},都将vstart CSR重置为零。应用程序不应该修改
vstart,当vstart!=0时,一些向量指令可能会引发非法指令异常。
Prestart部分,Body部分,Tail 部分,Active 元素, Inactive元素:

注意mask的语义是,每个bit对应一个元素,而不是每个bit对应一个bit
下图摘自:https://zhuanlan.zhihu.com/p/674158689。具体地,vstart, vl和遮罩向量(mask)控制了如何写到目的位置
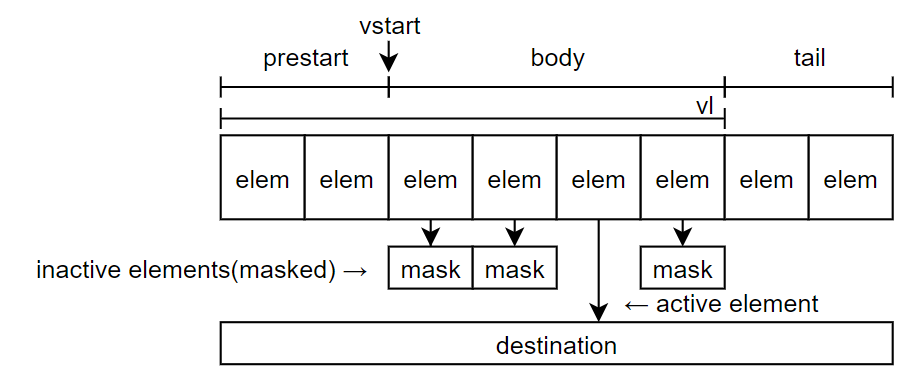
例子:VLEN = 128 bits, SEW = 32, LMUL = 8, vstart = 2
1 | Prestart部分[a0,a1] |
vtype
- 描述向量寄存器中数据元素的类型
- 只能使用vsetvl指令来动态配置vtype寄存器
vtype寄存器的位宽与架构的位宽一致
vtype.vsew字段:
动态设置数据元素的位宽。目前支持{8, 16, 32, 64}几种位宽。
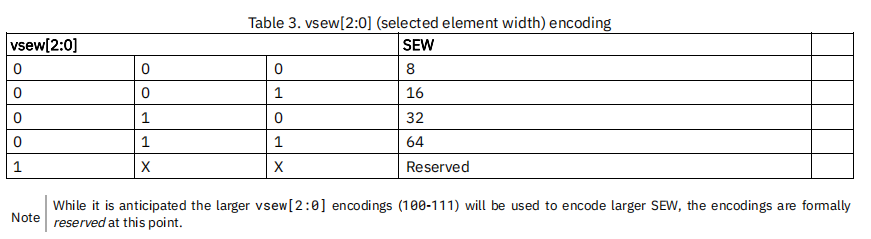
位宽对应C语言变量类型为:
| SEW | 对应的C语言类型 |
|---|---|
| 8 | i8,u8 |
| 16 | i16,u16,_Float16 |
| 32 | i32,u32,float |
| 64 | i64,u64,double |
vtype.vlmul字段:
指示具体多少个向量寄存器为一组;LMUL也可以是一个分数值{1/8,1/4, 1/2},但是需要满足如下约束条件:
1 | ELEN * EMUL >= SEW |
RVV支持扩宽或缩减指令,意味着向量指令的源操作数和目的操作数可能具有不同的位宽SEW,但元素个数是相同的,这意味着源操作数和目的操作数的LMUL可能不一致。具体见之前第一节加宽指令的例子。
注意:
当
LMUL= 2时,寄存器分组的第一个序号Vn必须为2的整数倍;样当LMUL= 4,Vn索引号必须为4的整数倍;同样当LMUL= 8,Vn索引号必须为8的整数倍。当
LMUL< 1,意味着只使用单个向量寄存器的一部分。向量寄存器中剩余部分(下图画横线部分)被视为尾部(Tail部分)的一部分,尾部元素必须服从vta设置。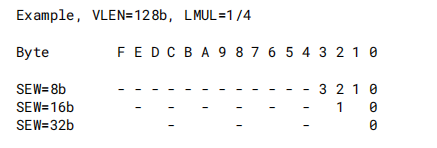
vtype.vma 和 vtype.vta字段:
vta(vector tail agnostic) 表示目标向量寄存器中tail数据元素的处理策略
vma(vector mask agnostic)表示inactive数据元素处理策略
分为两种策略:
- 不打扰策略(undisturbed): 目标向量寄存器中相应的数据元素保持原值不变
- 未知策略(agnostic):目标向量寄存器中相应的数据元素可以保持原值不变,也可以写入1
为什么要这样设置,有什么好处?见https://www.bilibili.com/video/BV1rjEWzeEGk/?spm_id_from=333.337.search-card.all.click&vd_source=7a39dbfc457222c1894595f42f7958fd

反汇编指令:
1 | ta # Tail agnostic,即末尾元素未知 |
注意:在v0.9 之前的spec版本,如果在vsetvl指令中没有指定vta和vma字段,则默认设置为tu和mu,即末尾元素不打扰,非活跃元素不打扰;但在v1.0 spec版本,不指定vta和vma字段的vsetvl指令已经被弃用,现在必需要设置,默认值可能是ta和ma,建议在使用vsetvl指令时明确指定vta和vma字段
vtype.vill字段:
当vsetvl指令尝试写入一个非法值到vtype寄存器中,vill字段会被置位,之后任何依赖这个vtype寄存器执行的指令都会触发一个非法指令异常。
vill字段被置位时,vtype寄存器中其他XLEN-1位为0
注意:vsetvl 以及 Vector Load/Store Whole Register 指令不依赖vtype寄存器,也即不受vill置位影响。
vxsat
只有第0位有效,其他位都为0;vxsat[0]用于指示定点指令是否做饱和处理;同时vxsat[0]位被镜像到vcsr寄存器中
vsrm
[1:0]位有效;vxrm[1:0]用于设置定点计算的rounding模式;vxrm[1:0]也被镜像到vcsr寄存器中
舍入(rounding)模式的计算公式如下:
1 | roundoff_unsigned(v, d) = (unsigned(v) >> d) + r |
其中:v 是输入值,d 是要右移的位数,r由舍入模式决定,r的取值在最后一列,有4种舍入模式:

vcsr
目前就仅仅包含vxsat[0]与vxrm[1:0]的镜像
复位时各CSR寄存器的值
- 建议硬件设计在reset时
vtype.vill位拉高,vtype寄存器中剩余的位为零,vl被设置为0。 - 大多数向量指令在使用时都需要使用
vsetvl指令初始化,vsetvl指令会重置vstartvxrmvxsat寄存器。
2.4 混合宽度运算
RVV允许不同宽度也就是不同SEW的元素进行运算,但是需要满足元素个数一致。即只要VLEN*LMUL/SEW相等,由于VLEN是一个常数,即SEW/LMUL 相等
下图每种分组都可以互相运算

3. 向量操作与标量操作
RVV指令分类:LOAD-FP,STORE-FP,向量操作指令OP-V,向量设置指令OP-V
RVV指令操作分类:一般分为两大类,一类是向量(vector)运算指令,另一类是标量(scalar)运算指令
向量与标量操作
- 向量运算:正对向量寄存器中所有通道的数据同时进行运算
- 标量运算:只对向量寄存器中第0个通道(最小编号)的数据或者与通用寄存器进行运算
| 对象 | 是否受LMUL参数控制 | |
|---|---|---|
| 标量操作 | 立即数,标量寄存器器(x0-x31),浮点寄存器(f0-f31),或向量寄存器的0号元素 | 否 |
| 向量操作 | 向量寄存器中所有通道的数据、同时 | 是 |
示例:指令中的x表示通用寄存器,s表示视作标量的向量寄存器组即第0个,v表示向量寄存器组,i表示立即数
1 | 标量运算:在标量x寄存器与向量寄存器的元素0之间传输单个值,不受LMUL参数影响 |
向量操作中的 SEW EEW LMUL EMUL参数
RVV向量操作都需要设置EEW(有效的元素位宽)和EMUL(有效寄存器组乘系数)。用来确定元素位宽和摆放位置,对于大多数指令EEW=SEW和EMUL=LMUL
注意: EMUL可以取不同值{1/8, 1/4, 1/2, 1, 2, 4, 8} 表明,向量操作数可能占据一个或多个向量寄存器,但编码中使用编号小的寄存器来指定这个向量寄存器组
比如:
1 | vmv1r.v v1, v2 # 将v1寄存器内容拷贝到v2 |
向量操作EMUL(或LMUL)满足如下约束:最大组数为8
1 | EMUL <= 8 (LMUL <= 8) |
注意:
- Prestart部分不会拷贝到目的寄存器
- Tail 部分是否拷贝到目的寄存器受
vta参数控制 - Inactive 元素是否拷贝到目的寄存器受
vma参数控制
向量掩码操作
向量指令的bit25位vm用来表明是否存在掩码操作。

当向量指令的bit25位vm = 0 代表指令存在掩码操作,vm = 1 表示一般指令(非掩码操作)
如下汇编指令:
1 | vop.v* v1, v2, v3, v0.t # enabled where v0.mask[i]=1, vm=0 |
- v0.t 表示掩码有效,其中.t表示ture,当v0.mask[i] = 1,控制的第i个元素进行vop操作
- 如果没有v0.t掩码,表示不进行掩码操作(vm=1)
注意:当前的RVV只支持一个向量掩码寄存器v0
4. 向量设置指令 vset{i}vl{i}
总结:设置vtype和vl
应用程序特性将要处理的元素总数(应用程序向量长度或AVL)作为输入,通过vsetvl指令计算,然后将计算得到的结果写入vl寄存器,每次处理vl个元素,迭代继续,直到所有元素都被处理完毕
RVV 提供3种形式的vsetvl指令用来设置vl 与 vtype寄存器:
1 | vsetvli rd, rs1, vtypei # rd = new vl, rs1 = AVL, vtypei = new vtype setting |
总结起来就是vset{i}vl{i},第一个i表示AVL是不是立即数,第二个i表示vtype是不是立即数
指令格式:
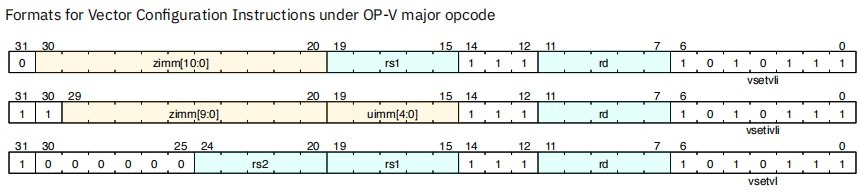
指令中:
- 入参AVL,即指令中的rs1或uimm,表示要处理的元素总数;
- 入参vtype,即指令中的vtypei 或 rs2,包含了元素宽度
vsew和 寄存器组乘系数vlmul等参数
指令完成动作:将vtypei值设置到vtype寄存器,计算得到vl值并写入vl寄存器,
- 返回值:将计算的vl值写入rd寄存器返回
设置vtype
1 | e8 # SEW=8b |
注意:如果设置不支持vtype值,则vtype中vill位将会被置位,vtype中剩余的其余位被设置为0,vl寄存器也被设置为0
如何计算vl值
注意RVV并不是能设置vl寄存器的,而是将AVL参数传递给vsetvl指令来设置正确的vl值

简单解释如下:
- 当rs1 非x0时,AVL = x[rs1],计算得到vl值,写入
vl寄存器,新的vl值也被写入rd寄存器中。 - 当rs1 为x0,rd 为非x0时,AVL = ~0,即AVL设置为最大整数值,这样将vlmax写入
vl寄存器,新的vl值也被写入rd寄存器中。 - 当rs1 rd 都为x0,表示
vl值不变,vl值不会更新到rd寄存器中(vtype 可能改变)
vl与AVL的关系:
1 | vl = min(AVL, VLMAX) // 其中VLMAX = LMUL*VLEN/SEW |
5. 向量加载存储指令
RVV优化的关键点是:数据的布局很重要,SIMD只适合处理规整的数据,我们需要将数据摆放“整齐”,然后进行向量运算。所以需要我们比较熟悉load & store指令。
指令格式:

RVV优化的关键点是:数据的布局很重要,SIMD只适合处理规整的数据,我们需要将数据摆放“整齐”,然后进行向量运算。所以需要我们比较熟悉load & store指令。
5.1RVV load & store 三种寻址模式
RVV load & store 指令支持三种寻址模式,分别为:
- Unit-Stride load & store, 即单位步长的load&store
- Strided load & store, 即跨步长的load&store
- Indexed load & store,即按索引的load & store,也称聚合加载/离散存储模式(gather-load/scatter-store)
5.1.1单位步长的load&store
load&store连续的内存数据
指令举例 v[l|e]e[8|16|32|64].v vd, (rs1), vm
1 | # vd 表示目的向量寄存器,rs1表示内存基地址, vm 表示掩码操作数 (v0.t or 空) |
intrinsics 示例:
1 |
|
打印结果为:
1 | res[16] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16}; |
5.1.2 即跨步长的load&store
跨步长的load&store 指令用来load&store间隔相等步长的内存数据(支持0间距或者步长为负值)。这个步长由 rs2 指定(单位为字节)
1 | # Vector strided loads and stores |
示例如下:
1 |
|
打印结果为:
1 | res[4] = {1, 5, 9, 13} |
注意:步长bstride 需设置为 SEW (以字节为单位)的整数倍,否则结果可能不符合预期。可能会截断数据
5.1.3 按索引的load&store
可以对指定index的元素进行load&store,指定的index存在一个向量里面,其每一个元素描述装载元素相对起始点的位置,index向量由vs2指定,单位为byte
使用按索引的load & store有如下几点要注意:
- 按索引的load & store 方式,首先需要先load index向量。(这一步是比单位步长和跨步长load多做的,所以按索引的load & store性能是最差)
- index向量描述的是相对起点的偏移,只能是正整数(从intrinsic中的index变量类型为无符号类型可以看出这点)。
- 按索引的load & store 可以实现单位步长和跨步长的load&store的效果,但性能是最差的;
按索引的load & store 支持以下两种形式:
- 有序索引(indexed-ordered):访问内存时按照索引的顺序有序地访问
- 无序索引(indexed-unordered):访问内存时不能保证数据元素的访问顺序
note: “unordered” only applies to non-idempotent memory (e.g. MMIO), but otherwise the operation is still sequential
默认情况下,这些元素的加载顺序是按地址顺序进行的。
但在某些实现中,可以优化为 无序加载,以便更高的吞吐量,例如乱序执行或并行访问。
如果你正在实现某个设备驱动或写操作系统内核(如访问 PLIC、UART 等),绝对不能用无序 load。需要显式屏蔽优化,保持顺序
指令举例:
- 无序索引(indexed-unordered):访问内存时不能保证数据元素的访问顺序
1 | Vector indexed loads and stores |
示例:
1 |
|
打印结果为:
1 | 8, 4, 11, 9 |
5.2 RVV segment load & store
RVV segment load & store:
- 单位步长的Sgement load&store (Sgement Unit-Stride load & store)
- 跨步长的Sgement load&store (Sgement Strided load & store)
- 按索引的Sgement load & store (Sgement Indexed load & store)
5.2.1 单位步长的Sgement load&store
nf:分成几个区域(可以理解为结构体里面有多少个元素,如struct {int a; int b},有两个)
eew:可以理解为每个元素多少bits
rs1:base addr
约束:nf * lmul <= 8
1 | # Format |
示例如下:
1 |
|
打印结果为:
1 | # 结果如下,可以实现一次segment load 分奇偶的目的 |
5.2.2 跨步长的Sgement load&store
相比5.2.1的单位步长 vlseg 多了一个rs2:代表byte-offset,单位为字节
注意load和store的单位是bytes,而不是c语言中的int &这种,在+1时两种方式有区别
1 | # Format |
示例如下:
1 |
|
打印结果为:
1 | vx[16] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} |
5.2.3 按索引的Sgement load & store
指令格式
1 | Format |
示例如下:
1 |
|
打印结果为:
1 | vx[16] = {8, 4, 11, 9} |
5.2.4 RVV Load/Store Whole Register 指令
当向量寄存器中的数据元素位宽或数量未知或者修改vl以及vtype寄存器的开销很大时,我们不能使用前文介绍的加载指令。RVV提供了另外一种加载全部向量数据的指令。加载全部向量数据的指令常常用于保存和恢复向量寄存器的值(如操作系统上下文切换)。
1 | # Format of whole register load and store instructions. |
注意:没有intrinsics API来对应RVV中的vmv<nr>r.v指令
5.2.5 首次异常加载指令(Unit-stride Fault-Only-First Loads)
有些场景我们无法确定要处理的数据长度,例如,在C语言中通过判断字符是否为’\0’确定字符串是否结束。而在向量加载指令中,如果加载了字符串结束后的数据,那么会造成非法访问,导致程序出错。
RVV引入了首次异常加载指令。首次异常加载指令常常用于待处理数据元素长度不确定的场合。
首次异常加载指令示例,可参考: https://github.com/riscv-non-isa/rvv-intrinsic-doc/blob/main/examples/rvv_strcpy.c
1 | # Vector unit-stride fault-only-first loads |
6. 整数算术指令
7.定点算术指令
8.浮点算术指令
9.Reduction指令
向量reduction操作接收一个向量寄存器组中的所有元素和一个向量寄存器第0个元素作为入参,结果存放到目标向量寄存器的第0个元素中
9.1 单宽度整数reduction
单宽整数reduction指令所有操作数与结果具有相同的SEW宽度,vredsum 算术和运算可能存在溢出。
1 | Simple reductions, where [*] denotes all active elements: |
9.2 扩宽整数reduction
对于vwredsumu.vs与vwredsum.vs两条指令,在求和之前,先扩宽为2SEW宽度,这样避免溢出。
1 | Unsigned sum reduction into double-width accumulator |
还有浮点指令的单宽度和扩宽reduction,这里不再讲述
10.Mask指令
操作向量寄存器掩码值;掩码操作数只能使用v0向量寄存器存放掩码。
汇编代码中有如下两种形式:
汇编代码中带有v0.t
v0.t 表示使用v0 向量寄存器作为掩码,每bit表示对应一个元素的状态。v0.mask[i]=1,表示第i个数据元素处于活跃状态;若v0.mask[i]=0,则表示第i个数据元素处于非活跃状态。
省略,即没有v0.t
表示目标操作数和源操作数中所有的数据元素都处于活跃状态。
代码示例如下:
1 |
|
日志打印如下:
1 | res[32] = {100, 101, 102, 103, 104, 105, 106, 107, 8, 109, 10, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131,} |
可见,只有a8与a10 没有参与加100的运算。
10.1向量mask逻辑指令
操作掩码寄存器v0
11.排列指令
v{f}mv.[f|s|x|v].[v|x|s|f]
11.1 标量mv指令
向量-标量Move指令,在标量x寄存器与向量寄存器的元素0之间传输单个值(这条指令会忽略LMUL参数)
1 | vmv.x.s rd, vs2 # x[rd] = vs2[0] (vs1=0) # 向量move到标量,注意:即使vstart>=vl或者vl=0,这条指令都会执行操作。 |
11.2 浮点标量mv指令
浮点-标量move指令,在标量f寄存器与向量寄存器的元素0之间传输单个值(这条指令会忽略LMUL参数)
1 | vfmv.f.s rd, vs2 # f[rd] = vs2[0] (rs1=0) |
11.3 向量滑动指令
11.4 向量寄存器收集指令
11.5 向量寄存器压缩指令
11.6 整个向量寄存器移动指令
intrinsic 编程
intrinsic:内嵌函数
推荐:《RISC-V Vector Programming in C with Intrinsics.pdf》
https://fprox.substack.com/p/risc-v-vector-programming-in-c-with
intrinsics 编程:在汇编语言上封装了一层,允许程序员使用类似于C/C++等高级语言的语法来调用特定的CPU指令,上手更加简单,程序可读性和可维护性更高。
RVV intrinsics其字段含义如下
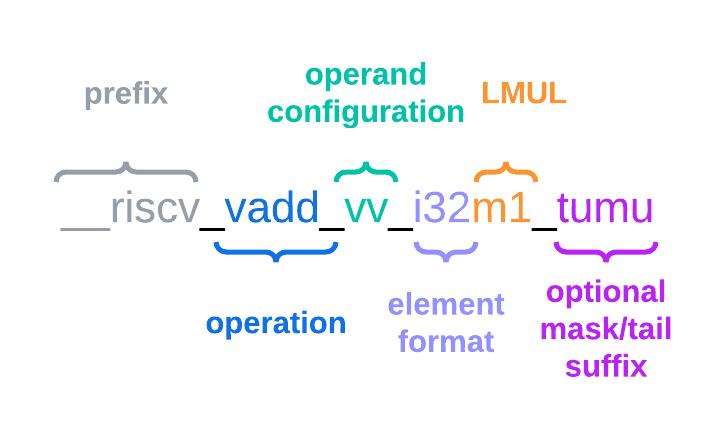
可以看到intrinsics包含一些指令编码以外的信息,如element size和lmu,这样能够简化编程模型(所有关于操作矢量的配置信息都嵌入到内在函数中)
大多数intrinsics都需要一个向量长度参数avl(即入参vl,vsetvl指令根据avl来设置vl寄存器)
operand configuration:vv、vx、vi
element format:对应SEW
optional mask/tail suffix:
后缀 寄存器值 含义 No suffix vm=1,vta=1非掩码,尾部元素未知(unmasked, tail-agnostic) _tu vm=1,vta=0非掩码,尾部元素不打扰(unmasked, tail-undisturbed) _m vm=0,vta=1,vma=1掩码,尾部元素未知,非活跃元素未知(masked, tail-agnostic, mask-agnostic) _tum vm=0,vta=0,vma=1掩码,尾部元素不打扰,非活跃元素未知(masked,tail-undisturbed, mask-agnostic) _mu vm=0,vta=1,vma=0掩码,尾部元素未知,非活跃元素不打扰(masked,tail-agnostic, mask-undisturbed) _tumu vm=0,vta=0,vma=0掩码,尾部元素不打扰,非活跃元素不打扰(masked,tail-undisturbed, mask-undisturbed) vm,vta,vma都有两种取值,按照组合应该有2*2*2=8种,为什么表格中只列出了6种
vma表示的是被掩码mask的元素策略,那么当没使用掩码,也就是vm=1时,vma取值是多少都无意义,也即没有这种后缀
从哪里查询RVV intrinsics APIs?
官方参考:https://github.com/riscv-non-isa/rvv-intrinsic-doc/tree/main
在线查询API:https://dzaima.github.io/intrinsics-viewer/
分为显式命名方案与隐式命名方案
- 显式intrinsics APIs 是不可重载的,显示的指明了
EEWLMUL等参数,由于显示intrinsics APIs在代码中显式地指定了执行状态,因此该方案可读性更好。如__riscv_vadd_vv_i32m4,推荐这种 - 隐式 intrinsics APIs 是可重载的,其省略了对
vtype的显示控制,旨在提供一个通用接口,让用户将不同的EEW和EMUL的值作为输入参数