算法笔记-杂乱版持续更新
算法模板:数学、二分、双指针、单调栈、单调队列、字典树、Z函数、dp、差分、堆、线段树
蓝桥杯省赛考点
统计结果如下:
知识点 出现次数
模拟 17
贪心 16
DP 14
枚举 11
数学 9
二分 8
数论 7
DFS 5
前缀和 5
推公式 5
快速幂 4
差分 4
双指针 4
状态压缩DP 4
思维题 4
BFS 3
树形DP 3
递推 3
字符串处理 3
排序 2
搜索 2
剪枝 2
递归 2
动态规划 2
分类讨论 2
线性DP 2
最大公约数 2
二叉树 2
背包问题 2
找规律 2
并查集 2
哈希表 2
分解质因数 2
堆 2
结论题 1
树的直径 1
斐波那契数列性质 1
龟速乘 1
树状数组 1
归并排序 1
矩阵乘法 1
哈希 1
区间DP 1
辗转相减法 1
图论 1
环 1
置换群 1
完全背包问题 1
扫描线 1
线段树 1
Flood Fill 1
均值不等式 1
滑动窗口 1
平衡树 1
STL Set 1
IDA* 1
日期问题 1
贡献法 1
Bellman-Ford 1
SPFA 1
Dijkstra 1
组合计数 1
栈 1
括号序列 1
博弈论 1
构造 1
图的遍历 1
概率论 1
数学期望 1
逆元 1
快速选择 1
链表 1
排序不等式 1
多路归并 1
整数分块 1
整除 1
单调队列 1
欧拉函数 1
状态机 1
区间合并 1
蓝桥杯官方刷题
python刷算法技巧/知识
python 蓝桥杯之常用的库_蓝桥杯python库-CSDN博客
【蓝桥杯】Python自带编辑器IDLE的使用教程_python蓝桥杯编译器-CSDN博客
蓝桥杯 python组IDLE的使用方法_蓝桥杯能打开idle自带的文档吗-CSDN博客
F1打开帮助文档!!!
map事实上是返回一个迭代器
注意如果在函数里面需要使用一个全局变量
global ansnonlocal ans先像上面这两种方法声明一下
区分
t[::-1]和t[:-1]- 前者:用于反转序列,返回序列的反向版本
- 后者: 用于获取序列的子序列,该子序列包含从序列的第一个元素到倒数第二个元素(不包括最后一个元素),没有反转
格式化输出
1
2
3# 格式化输出十进制
decimal_format = "The number in decimal is: %d" % number
print(decimal_format) # 输出: The number in decimal is: 255python正无穷:inf,需要先从math引入
1
from math import inf
isqrt(mid//i) 比 int(sqrt(mid//i))快很多吗,大概五倍,也要从math库引入1
from math import inf
join的使用1
print(' '.join(i for i in map(str,path)))
python里面自己来调用 min,max很慢,如果觉得很慢可以自己拆开了用if,else来写。那么怎么定义”很慢“呢?
输入
1
2#读取n个数
a = list(map(int, input().split()))输入数据太多比如10^5以上建议用 sys.stdin
1
2import sys
input = lambda : sys.stdin.readline().strip()s.sort()和sorted(s)的区别:(一般习惯用s.sort())注意s.sort() 直接在s里面修改,不会返回一个新的
但是 sorted(s) 不会在s里面修改,而是返回一个新的
创建多维数组:
比如 n*m 的数组,注意先 m 后 n
1
a = [[ 0 for _ in range(m)] for _ in range(n)]
创建一个a * b *c 的数组,初始化为全0
1
f = [[[0 for _ in range(c)] for _ in range(b)] for _ in range()]
min(列表1的一部分,列表1的另一部分)是不可以的
在Python中,
min函数不能直接接受两个列表作为参数,然后比较这两部分来决定最小值。min函数期望的是一个可迭代对象,从中它会找到最小值。如果你尝试将两个列表作为参数传递给min,你将得到一个类型错误,因为min函数不知道如何比较两个列表。手动实现上取整:
1 | (x+mid-1)//mid #这一步,实现上取整,怎么实现的? |
python自带的bisect使用:
bisect_left:(最左)如果要查找 最左边的,使用bisect_left 找如果要插入,应该插入的最左端位置,如果列表中已经存在该元素,它将返回该元素在列表中的最左侧位置
bisect_right:(最右)返回的是插入点的右侧位置,即如果列表中已经存在该元素,它将返回该元素在列表中的最右侧位置
bisect:
bisect是bisect_right的别名,所以它的使用方式与bisect_right完全相同1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16from bisect import *
# 有序列表
a = [1, 3, 5, 7, 9]
# 要插入的元素
x = 5
# 使用bisect_left找到插入点
index = bisect.bisect_left(a, x)
print("插入点的索引:", index)
# 输出: 插入点的索引: 2
index = bisect.bisect_right(a, x)
print("插入点的索引:", index) # 输出: 插入点的索引: 3其实列表就是栈,Python中列表的实现是基于链表来的,python中的列表里的pop()可以实现出栈,append()实现入栈,而这两个操作的时间复杂度都是o(1),所以列表本身就是一个栈,实现队列的话用pop(0)实现出队,append()实现入队,只不过这里的pop(0)的时间复杂度是o(n)
所以队列最好还是用deque的popleft和append,这两个时间复杂度是o(1)
使用队列:
1
2
3
4
5
6
7
8
9
10import collections
q = collections.deque()
#左端出队
q.pop_left()
#右端入队
q.append()
#判断队列是否为空
len(q) > 0熟悉一下文件操作,可能需要你打开文件?
逆元,博弈
排序:按照某个key排序
按照元组的第二个元素排序:
1
2arr = [(1, 3), (4, 1), (2, 2), (5, 0)]
arr.sort(key=lambda x: x[1])按照字典的某个键排序:
1
2# 使用 sort 方法按字典的 'age' 键排序
arr.sort(key=lambda x: x['age'])
千万不要像这样初始化数组:
1
nums = [[0,0]]*n
使用列表推导式而不是乘法的原因是,乘法会创建对同一个列表对象的多个引用,这可能会导致意外的副作用。例如:
1
2
3
4
5
6
7python复制代码# 错误的方法:使用乘法
n = 5
my_list = [[0, 0]] * n
# 修改一个元素会影响所有元素,因为它们引用的是同一个对象
my_list[0][0] = 1
print(my_list) # 输出 [[1, 0], [1, 0], [1, 0], [1, 0], [1, 0]]在上面的例子中,
[[0, 0]] * n会创建一个包含对同一个[0, 0]列表的n个引用的列表。因此,修改其中一个元素会导致所有元素都发生变化。因此,推荐使用列表推导式来避免这种问题:
1
2
3
4
5
6python复制代码n = 5
my_list = [[0, 0] for _ in range(n)]
# 修改一个元素不会影响其他元素
my_list[0][0] = 1
print(my_list) # 输出 [[1, 0], [0, 0], [0, 0], [0, 0], [0, 0]]这样可以确保每个元素都是独立的
[0, 0]列表,不会相互影响。python对部分数组排序
1
2
3tmp[i:j+1] = sorted(tmp[i:j+1])
# tmp[i:j+1].sort()是错误的,不会作用于原数组
# 创建的是原数组的一个切片(即一个新的列表),并对这个新的列表进行排序,而不会影响原数组ascii转字符串:
chr()字符串转ascii:
ord()四舍五入: round(n)
由数据范围反推算法复杂度以及算法内容

1.数学
1.2试除法判定质数
质数: > 1且约数只包含1 和本身
性质: d | n, (n/d) | n
因此n的所有约数其实都是成对出现的,因此我们可以每次只枚举每一对里面较小的那一个,也就是满足 d <= n/d,整理一下就得到 d <= 根号n,因此我们只需要枚举到根号n就可以,从而降低了时间复杂度
n中最多只包含一个大于sqrt(n)的质因子,如果有两个,相乘不就 > n了吗
快速求因数
只用从 $1$ 到 $\sqrt{n}$ 枚举因数,另一个因数就等于 $n \div 当前因数$ ,必被整除的
1 | for x in nums1: |
快速排序
- 确定分界点,q[(l+r)//2] or q[random]
- 调整区间: 让所有 <=x 的在x左边,>= x的在x右边
- 递归处理左右区间
最难实现的就是第二步了:
容易想到但是不优美的做法:
可以开两个额外的数组,把 <= x的放在一个,>=x 的放在另一个,最后把他们俩拼起来
优雅做法:
- 用两个指针,其中 i 指向第一个,j 指向最后一个
- 遇到 <=x 的数,i++,直到遇到第一个 >x 的数,停下
- 遇到 >=x 的数,j–,直到遇到第一个 <x 的数,停下
- 交换 i 和 j 对应的数
- 循环直到 i > j
1.3离散化
数的值域很大,但是范围不大(稀疏),需要用到数的值做下标,但是又不可能开那么大的全局数组,于是需要离散化:把数值映射
需要解决的问题:
- 去重(先排序后unique去重)
- 如何算出 x 离散化之后的值(二分)
一般来说 10的五次方以内差不多
把下标在 i 的值,映射到一个数
1.4模运算
分享丨模运算的世界:当加减乘除遇上取模 - 力扣(LeetCode)
加法和乘法的取模:
$$
(a+b)\ mod\ m=((a\ mod\ m)+(b\ mod\ m))\ mod\ m
$$
$$
(a b)\ mod\ m=((a\ mod\ m)(b\ mod\ m))\ mod\ m
$$
负数的取模: $x<0$ ,$y>=0$,则 $x \equiv y\ mod\ m$ 等价于
$$
x\ mod\ m+m=y\ mod\ m
$$
除法的取模:如果 𝑝 是一个质数,𝑎是 𝑏的倍数且 𝑏和 𝑝互质(𝑏不是 𝑝的倍数),那么有
$$
\frac{a}{b}\ mod\ p =(a*b^{p-2})\ mod\ p
$$
总结
代码实现时,上面的加减乘除通常是这样写的:
1 | MOD = 1_000_000_007 |
1.5 gcd 与 lcm
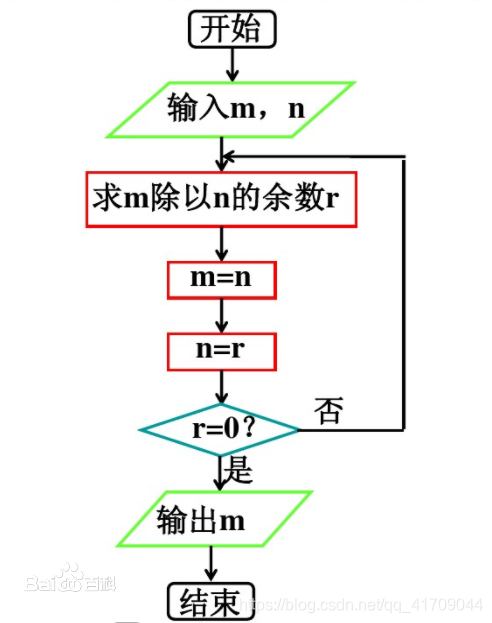
1 | def gcd(a,b): |
gcd(a,b) = gcd(b,a)
2.双指针 变长滑动窗口
两数之和,三数之和:
- 什么时候可以使用双指针?
- 双指针要求一定要排序,排序之后元素对应的下标就变了
- 因此如果题目要求返回元素数值我们就可以使用双指针
- 使用hash表
- 题目要求返回下标时
双指针要满足单调性
在什么时候移动指针
什么时候记录答案要搞清楚
713. 乘积小于 K 的子数组 - 力扣(LeetCode)
[3. 无重复字符的最长子串 - 力扣(LeetCode)](
3.二分
红蓝染色法理解二分
我们以寻找到 >= x 的第一个下标来举例:
你的条件可以灵活定义
用红色表示不满足条件的,蓝色表示满足条件的,白色表示不确定
核心:
- 你要维护的区间内的都是没有染色的,区间的定义是未染色的范围,而不是答案的范围!!!
- l 和 r 的初始值怎么定义?看你初始的不知道如何染色的区间范围(白色)是多少,以及你二分是使用闭区间 or 开区间 or 左闭右开 哪种策略编写的,据此定下来你的 l 和 r值
- 循环条件如何终止?当你的区间不为空的时候循环
- 中间判断了之后 l,r 与 m 的关系应该怎么变化:看你想要寻找什么
- 最后答案应该怎么return:在找第一个 >= x 的情况下你要return的应该是蓝色(true)的第一个
mid 表示正在询问的数
闭区间写法下我们如何取得答案?
有一个循环不变量保持着:
- L-1始终是红色
- R+1始终是蓝色
- 那么答案其实就是 蓝色的第一个,也就是L或者R+1
多种写法
一般求什么就二分什么
三种写法:推荐开区间,中间l,r,m之间的判断关系简单
1 | # 找 >= target 的第一个 |
那么一共演变了四种题型:
1 | >= x 这种是我们熟知的 |
如果说target比所有的数都大的话:会返回数组最大下标的next
target比所有的数都小的话:会返回 0
target在最大最小范围内,但是没有target,会返回 >= target 的第一个
python 写二分最好还是直接调用库,这样比较快,大概快一半
1 | from bisect import * |
162
https://leetcode.cn/problems/find-peak-element/
1 | #红色代表峰顶左边 |
153
原题链接: 153. 寻找旋转排序数组中的最小值 - 力扣(LeetCode)
分析
这题一共就两种情况,因为是对一个有序数组的旋转,看下面画的图
第一种情况很好解决,简单的二分,第二种情况需要分析一下
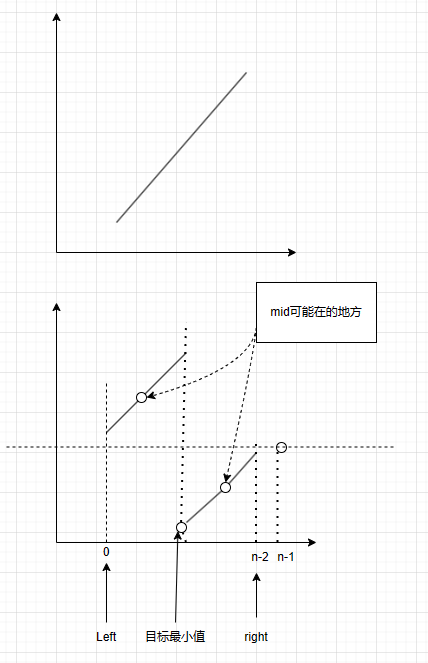
我们要找的相当于是谷底,也就是左右都比他大的
红蓝染色法二分:
- 红色表示最小数的左边
- 蓝色表示最小数或者最小数的右边
我们可以首先确定最后一个数一定是蓝色,所以开始的区间可以设为 [0,n-2],这个区间是我们不知道要怎么染色的,接下来开始二分缩小这个区间
使用开区间来写的话,最初 l = -1,r = n-1
那么我们怎么确定要染什么颜色?
- 通过已知条件来看,我们仿照上一题,让mid和mid+1来比较可以吗?显然是不行的,因为除了最小值旁边的元素其他位置都满足 num[mid] < num[mid+1] ,无法根据这个来染色
- 可以根据 num[mid] 和 num[-1] (最后一个元素) 来比较
- 如果 num[mid] < num[-1]:由图可知,需要让 r = mid
- 如果 num[mid] > num[-1]:由图可知:需要让 l = mid
最后返回值应该是什么呢,下标返回 r 即可
code
1 | # 这题不就是寻找谷值吗 |
思考:
边界条件,最小的在最右怎么办?
- 这种情况由于一开始其实我们就给最右染色了,那么 r 一直是不会移动的,合理
一般最大化最小值或者最小化最大值都可以用二分来做
4.单调栈
单调栈:如果你发现你要计算的内容和上一个更大(小)/下一个更大/(小)的元素有关,尝试单调栈
栈中保存有用的,维护它的单调性【这一点是最难的,你如果知道需要保留什么,就知道什么东西需要入栈,什么东西需要出栈,在什么时候计算答案】
可以在进栈 or 出栈的时候来做你想做的
从左往右
1 | class Solution: |
从右往左:
现在的是 x,弹出栈中所有 <= x的数(弹出意味着这些数没有用了,为什么呢,是因为x把右边的全部遮住了,我们左边的所有数的答案都不可能是和遮住的这些数有关)
那为什么比更大的数还要保留呢,如果一个数比x大并且小于这个栈顶更大的数,那么这个数的答案就是我们提到的更大的数
然后放入栈,x的答案是在发现栈为空(此时不用操作,初始化时已经设置为了0)或者栈顶元素比自己大了,此时可以算x对应的答案,然后放入x
1 | class Solution: |
注意最后,栈不一定是空的
个人更偏向从左往右
对栈顶元素找上一个更大的元素,在找的过程中填坑
横着计算,看成水泥,填平了,那么 <= 自己的高度就不需要了,因为已经填平
需要的下标:当前元素的下标,栈顶元素的下标,栈顶元素的上一个的下标
这个栈里面存的是从右往左能看到的东西
每次必入栈,出栈不一定
1 | class Solution: |
时间复杂度
需要特别注意,在数组的开头和末尾各自加上一个0 如果开头不加上0,会出现越界访问;如果末尾不加上0,会出现这种数据没有结果 5,1 2 3 4 5。原理是让最后一个0来让前面的所有没有更新的出栈更新至少一次
5.单调队列
及时去掉无用数据,保证双端队列有序
滑动窗口最大值
deque里面存的是下标
1 | class Solution: |
复杂度:每个下标最多入队出队各一次,所以复杂度是O(n)
当前数字 >= 队尾,弹出队尾
弹出队首不在窗口内的元素
1438. 绝对差不超过限制的最长连续子数组 - 力扣(LeetCode)
1 | def dq(nums,limit): |
注意这是没有 k 限制的滑动窗口
然后 ret = max(ret,i-left+1) 这里不能写成 ret = max(ret,i-min(q_max[0],q_min[0])+1),因为窗口最左端的索引有可能已经被顶掉了,看下面这个样例。 nums = [4,10,2,6,1] limit = 10
所以需要额外的信息来保存最左端的索引
1438. 绝对差不超过限制的最长连续子数组 - 力扣(LeetCode)
https://leetcode.cn/problems/longest-substring-without-repeating-characters/)
6.字典树
注意下面所说的字母和字符串的区别
- 把字符串按照前缀分组,第一个字母相同的,分到一组,第二个字母相同的,分到另一组….
- 用一颗树来实现
- 把每个字母对应到一颗树上的某个节点,保证对于每个字符串s内部,s[i]一定是s[i+1]的父节点
字典树可以用来快速判断一个字符串是否是另一个字符串的前缀,但是没办法判断后缀
后缀可以转为前缀 ,从后往前建树和查找不就行了
可以用两个前缀树,但是可以转化,把这两个信息整合到一个pair
什么时候想到用字典树呢,分组,组里面还有更小的组,这种就可能需要树:本质就是用树来分组
1 | class Trie: |
入门字典树:208. 实现 Trie (前缀树) - 力扣(LeetCode)
最大异或和
421. 数组中两个数的最大异或值 - 力扣(LeetCode)
7.Z函数 扩展kmp
但实际上和kmp没什么关系
计算每个后缀能和字符串开头匹配多长
利用已经匹配的信息
z-box右侧的字符都是没有见过的
回溯
回溯三问!!!
- 当前操作
- 子问题?
- 下一个子问题?
8.dp
如何手动记忆化搜索
核心是两点:
- dfs改成数组
- 递归改成循环
1 | # 由于有两个背包,所以二维肯定不行 |
注意看,if f[i][j][k] != -1 return f[i][j][k] 这一行就是利用记忆化搜索了
然后注意更新数组的位置 f[i][j][k] = max(suma,sumb) 别忘记了
在每次return之前更新对应的dp数组,然后dp数组的初始值可以给一个不可能达到的值,后面判断是不是这个值就可以知道是否搜索过了,从而实现记忆化搜索
注意你的结果是return dfs的结果而不是dp数组
dfs.cache_clear() # 防止爆内存
记忆化搜索:
3154. 到达第 K 级台阶的方案数 - 力扣(LeetCode)
注意如果很难确定数组大小,用hash表
注意遇到需要记录的dp数组,右边应该是dfs结果而不是dp数组结果
1 | #正确 |
记忆化搜索翻译为递推时,要注意循环的顺序,看你是从什么转移过来的
- 从i+1这种更大的转移过来,那么就需要反序枚举
- 从i-1这种更小的转移过来,那么就需要正序枚举
还要注意是否增加下标防止数组越界,也就是看有没有-1的出现和n的出现(数组最大下标为n-)
背包

- 恰好:dfs时必须等于0才记录答案
- 至多:dfs时>=0记录答案,然后初始化要变一下
- 至少:这个没看懂
看评论七水佬的总结
递推的初始值就是递归的边界
判断一维数组时是否需要反序遍历,自己根据状态转移方程列一个表来比较看一下
在只用一个一维数组的情况下,要注意转移来源 1. 不能被覆盖 2. 必须已经计算出来。按照这个要求,正序遍历会导致 0-1 背包状态被覆盖,而完全背包则是正确的(转移来源被计算出来,且不存在被覆盖的问题);逆序遍历对于 0-1 背包是正确的(转移来源是上一行的,早就被计算出来了且没有被覆盖),而完全背包则不行(转移来源没有被计算出来)。
像这样画个图就很好理解

1 | class Solution: |
类似背包问题循环顺序的思考:
假设你现在在c,要转移到(i+1,c)你转移的其中一个肯定是(i,c)
那么对于另一个,如果你是从图中这两个蓝色框转移过来,那么需要倒序遍历
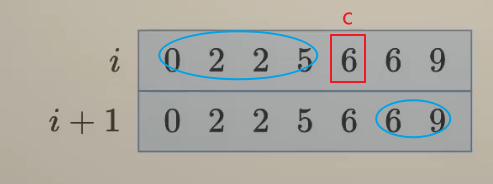
- 左上蓝色圈分析:你需要从一个左边的旧值转移过来,你如果正序遍历,那么左边的旧值会被新值覆盖,导致错误
- 右下蓝色圈分析:你需要从一个右边的新值转移过来,如果正序遍历,你得到的右边的还没有更新,还是旧值
如果是从这两个绿色框转移过来,那么需要正序遍历:

- 左下绿色圈分析:你需要从一个左边的新值转移过来,那么就要从左到右依次更新,如果你倒序遍历,左边的还是旧值没有更新
- 右上绿色圈分析:你需要一个右边的旧值转移过来,那么不能从右边更新过来,如果倒序遍历,右边的旧值会被新值覆盖,导致错误
如果察觉到重复的子问题,就可以使用动态规划(记忆化搜索)
从第一个或者最后一个开始思考?
如何满足恰好? 在dfs返回值的时候判断此时背包剩余容量是不是0
线性dp
前缀或者后缀
区间dp
不再是前缀或者后缀,而是数组中间的区间
核心思想是分治法?
1039. 多边形三角剖分的最低得分 - 力扣(LeetCode)
状态压缩dp
一般看到很小的数据范围,就有可能是一个状压dp,什么十几啊这种
9.差分数组
分享|【算法小课堂】差分数组(Python/Java/C++/Go/JS) - 力扣(LeetCode)
优化对区间每个数都加/减同一个数的操作
记录变化量来优化
也可以这样理解,d[i] 表示把下标 >= i 的数都加上 d[i]。
性质 1:从左到右累加 𝑑 中的元素,可以得到数组 𝑎
代码模板
1 | # 你有一个长为 n 的数组 a,一开始所有元素均为 0。 |
这题目前还看不懂:2528. 最大化城市的最小电量 - 力扣(LeetCode)
10.堆,优先队列
1046. 最后一块石头的重量 - 力扣(LeetCode)
手写小顶堆:1046. 最后一块石头的重量 - 力扣(LeetCode)
python库实现的是小顶堆:heapq 是 Python 中的一个内置模块(不需要导入?)
1 | import heapq |
堆顶就是第0个元素
如果你需要实现大顶堆(最大优先队列),可以通过将优先级的值取负来实现:
11.树状数组,线段树
https://www.bilibili.com/video/BV1ce411u7qP
动机,我们想修改一个点,然后查询某个区间的和
可选的方法:
- 维护 $n^2$ 个区间的和:此时查询是 $O(1)$,但是更新某个点是$O(n^2)$
- 把每个区间分成单个,也就是[1,1], [2,2] .. [n,n],这样的话更新某个点是$O(1)$,查询是$O(n)$
这里查询和更新就像天平的两端,你需要做一个tradeoff
那么我们试着把维护的区间多一点,但是又不至于到 $n^2$ 个
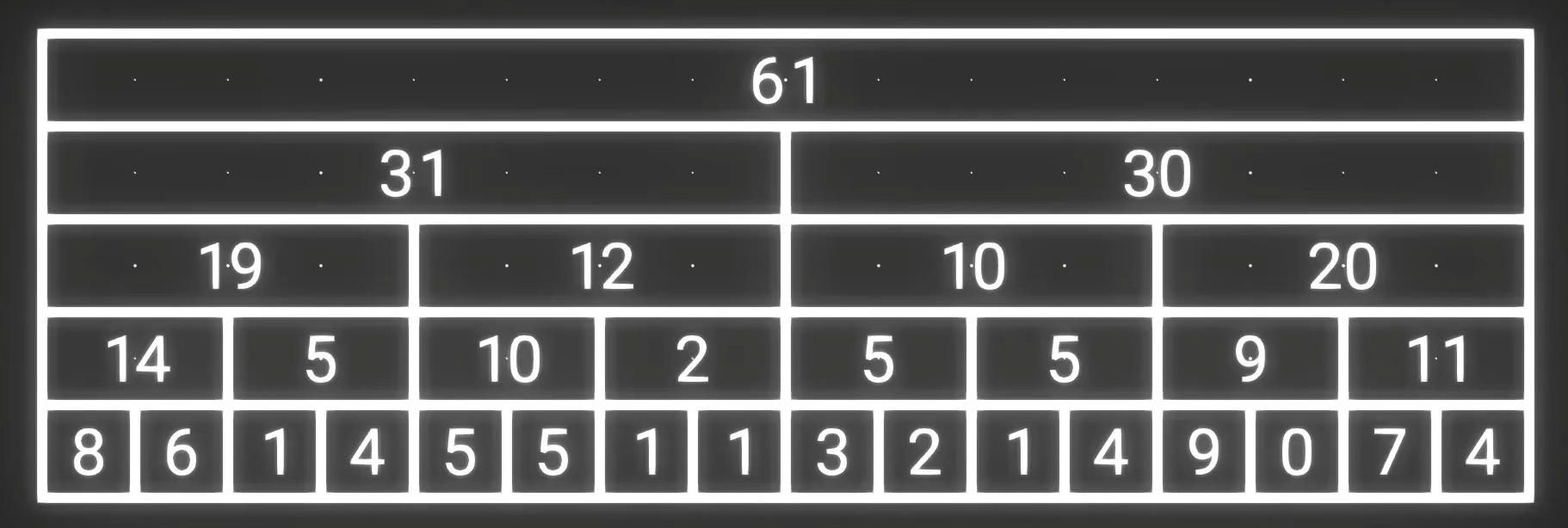
像这张图一样:此时我们要查询某个区间的和,复杂度其实降到了$O(logn)$
上面看上去就像树形结构了,好了,此时你就发明了线段树了()
代码实现:
首先我们需要开多大的数组,图上面这个数组最下面一层16,然后8,4,2,1
$16+8+4+2+1=31$
你的数组长度要差不多 $2^{n的二进制长度}*2$ 或者 4n
把最下面一层补满
树状数组:单点更新,区间查询
线段树:区间更新(都加上一个数、把子数组内的元素取反),区间查询
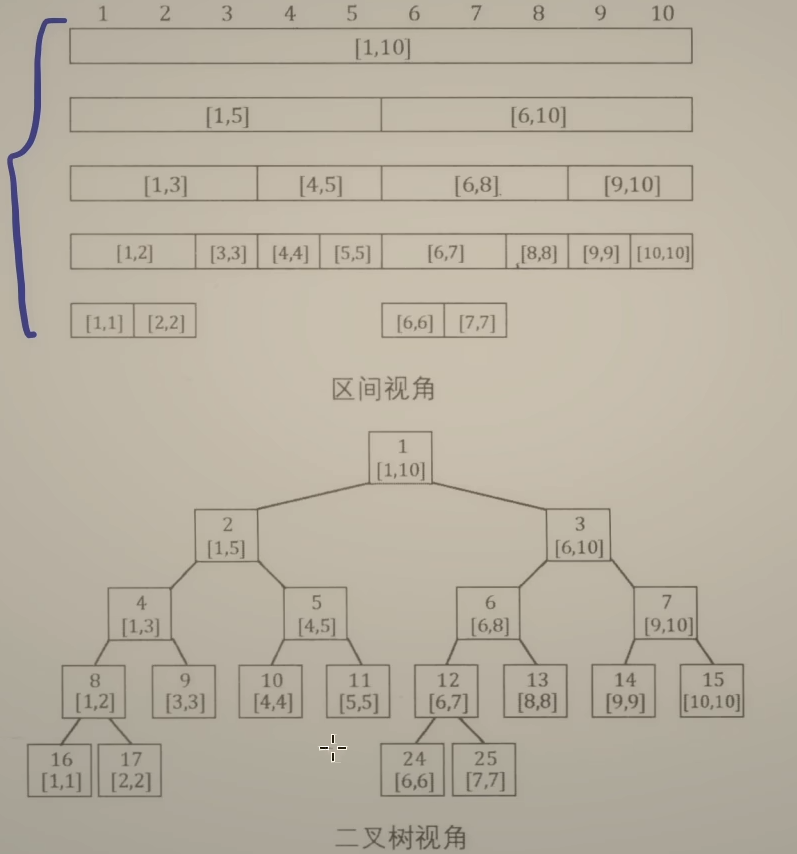
两大思想:
挑选O(n)个特殊区间,使得任意一个区间可以拆分为O(logn)个特殊区间
特殊区间个数 <= 4n
最坏情况下,左边走到叶子结点,右边走到叶子结点,一共就拆分了2*树高 = 2 *logn个区间,也可以最近公共祖先来思考
o 表示结点编号
特别注意:由于o和0离得比较近切像,不要打错了!!!
1 | def build(o:int, l:int, r:int):#相当于自底向上建树 |
单点修改不用lazy?区间修改才用lazy
单点修改直接到底了 不需要lazy延迟?
lazy更新
如果说我要更新的区间被完全包含在了这次更新的区间内,那就不继续往下走,而是添加一个lazy tag
如果这个区间在后续的更新、查询被破坏掉了,就把lazy tag往下传
lazy标记下,区间修改和查询操作的实现
1 | todo = [0]*4*n #todo数组表示lazy标记 |
如果要实现区间修改为某个值而不是加上某一个值的话:把+=改为=
注意,下面这个是oi-wiki的模板,不是我的,等待修改为我的版本
1 | def update(o:int, l:int, r:int, L:int, R:int, c:int): |
资源
灵神主页题单:灵茶山艾府 - 力扣(LeetCode) 在讨论发布里面
分享|从集合论到位运算,常见位运算技巧分类总结! - 力扣(LeetCode)
1 | n,p,q = map(int,input().split()) |