xv6-multithread-switch
xv6任务切换详细分析,可以说是我认为xv6中最难的几个点之一,涉及到很多跳转,锁的运用
chapter7 多线程
进程和线程在这里好像没有特别做区分?是吗
一个进程对应一个线程
Linux,允许在一个用户进程中包含多个线程,进程中的多个线程共享进程的地址空间
学生提问:我们这里一直在说线程,但是从我看来XV6的实现中,一个进程就只有一个线程,有没有可能一个进程有多个线程?
Robert教授:我们这里的用词的确有点让人混淆。在XV6中,一个进程要么在用户空间执行指令,要么是在内核空间执行指令,要么它的状态被保存在context和trapframe中,并且没有执行任何指令。这里该怎么称呼它呢?你可以根据自己的喜好来称呼它,对于我来说,每个进程有两个线程,一个用户空间线程,一个内核空间线程,并且存在限制使得一个进程要么运行在用户空间线程,要么为了执行系统调用或者响应中断而运行在内核空间线程 ,但是永远也不会两者同时运行。
线程概述
为什么需要线程
- 有可能计算机需要执行分时复用的任务,例如MIT的公共计算机系统Athena允许多个用户同时登陆一台计算机,并运行各自的进程。
- 多线程可以让程序的结构变得简单(比如fork实现素数筛)
- 使用多线程可以通过并行运算,在拥有多核CPU的计算机上获得更快的处理速度
一个线程可以认为是串行执行代码的单元,它只占用一个CPU并且以普通的方式一个接一个的执行指令
线程的状态
我们可以随时保存线程的状态并暂停线程的运行,并在之后通过恢复状态来恢复线程的运行
- PC寄存器,表示当前线程执行指令的位置
- 保存变量的寄存器
- 栈(通常来说每个线程都有属于自己的stack)
线程管理
我们主要关注一个CPU在多个线程之间来回切换
多个线程都在这一个地址空间内运行,并且它们可以看到彼此的更新。比如说共享一个地址空间的线程修改了一个变量,共享地址空间的另一个线程可以看到变量的修改。所以当多个线程运行在一个共享地址空间时,我们需要用到锁。
XV6内核共享了内存,并且XV6支持内核线程的概念,对于每个用户进程都有一个内核线程来执行来自用户进程的系统调用。所有的内核线程都共享了内核内存,所以XV6的内核线程的确会共享内存
另一方面,XV6还有另外一种线程。每一个用户进程都有独立的内存地址空间,并且包含了一个线程,这个线程控制了用户进程代码指令的执行。所以XV6中的用户线程之间没有共享内存
还有一些其他的方式可以支持在一台计算机上交织的运行多个任务,可以搜索event-driven programming或者state machine
线程调度
主要解决:
- 如何实现线程切换,停止一个线程的运行然后启动另一个线程的运行?
- 切换线程时涉及到保存和回复线程状态,你要决定哪些信息是必须保存的,在哪里保存? context上下文,保存在proc或者cpu中
- 如何处理运算密集型线程(compute bound thread),这样的线程并不能自愿的出让CPU给其他的线程运行。所以这里需要能从长时间运行的运算密集型线程撤回对于CPU的控制,将其放置于一边,稍后再运行它
如何处理运算密集型线程(我的理解就是长时间占用CPU的线程):
利用定时器中断。位于内核的定时器中断处理程序,会自愿的将CPU出让(yield)给线程调度器,并告诉线程调度器说,你可以让一些其他的线程运行了。
基本流程是,定时器中断将CPU控制权给到内核,内核再自愿的出让CPU
XV6为每个CPU核都创建了一个线程调度器(Scheduler),他本身就是一个线程,不过专门用来调度的。每个线程都运行scheduler函数
在执行线程调度的时候,操作系统需要能区分几类线程:
- RUNNING:当前在CPU上运行的线程
- RUNABLE:一旦CPU有空闲时间就想要运行在CPU上的线程
- SLEEPING:以及不想运行在CPU上的线程,因为这些线程可能在等待I/O或者其他事件
定时器中断实际上就是把一个RUNNING线程转换成一个RUNABLE线程
当用户程序在运行时,实际上是用户进程中的一个用户线程在运行
如果XV6内核决定从一个用户进程a切换到另一个用户进程b
第一个用户进程a通过中断/系统调用等从用户空间陷入内核空间,此时是他对应的内核线程 a’
内核线程 a’ 通过swtch函数切换到了调度器线程,调度器线程执行scheduler来寻找要切换到的线程b
调度器线程通过swtch函数切换到了另一个用户进程b
之后再在第二个进程的内核线程中返回到用户空间的第二个进程,这里返回也是通过恢复trapframe中保存的用户进程状态完成。
为什么需要一个调度器线程作为媒介?
因为我们要执行调度程序scheduler,如果在旧进程的内核栈上执行是不安全的:其他一些核心可能会唤醒进程并运行它,而在两个不同的核心上使用同一个栈将是一场灾难,因此需要一个专门的调度线程专门调度
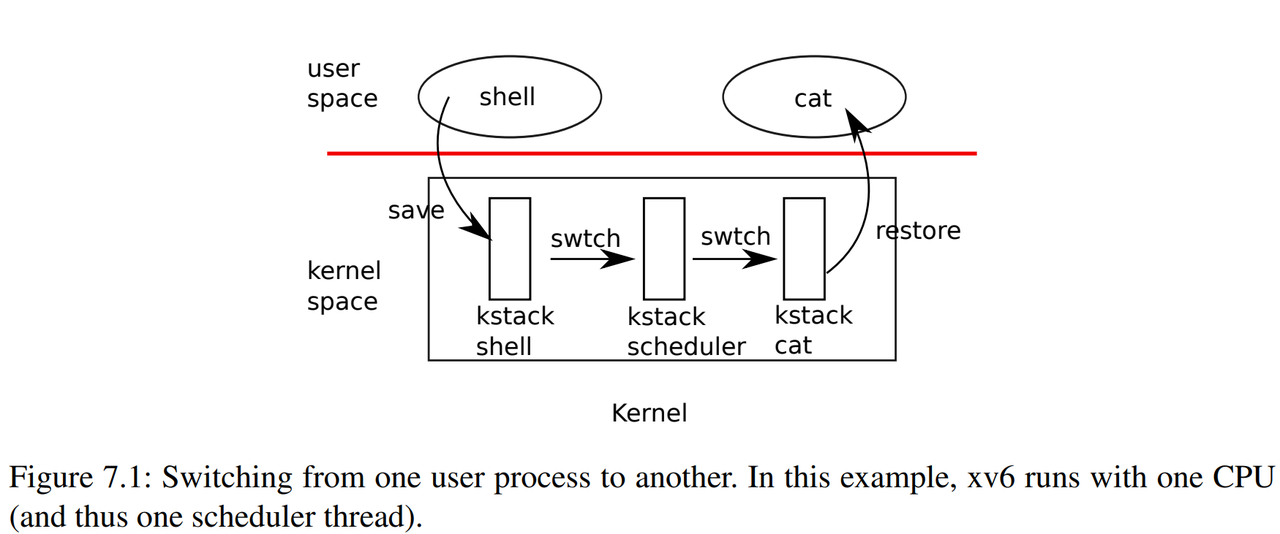
也就是在XV6中,任何时候都需要经历:
- 从一个用户进程切换到另一个用户进程,都需要从第一个用户进程接入到内核中,保存用户进程的状态并运行第一个用户进程的内核线程。
- 再从第一个用户进程的内核线程切换到第二个用户进程的内核线程。
- 之后,第二个用户进程的内核线程暂停自己,并恢复第二个用户进程的用户寄存器。
- 最后返回到第二个用户进程继续执行。
一个线程切换的例子:
时钟中断在usertrap中调用了yield -> yield调用sched -> sched调用swtch保存当前上下文,并且切换到调度器线程的上下文 -> 调度器执行调度程序scheduler找到一个可以运行的进程 -> 然后调度器线程swtch到找到的线程 -> 如果找到的这个线程以前执行过,那么他一定也是从swtch这里进入的(因为如果要暂停这个进程需要任务调度使用swtch切换),现在返回也是到他以前调用swtch指令的地方
以cc切换到ls为例,且ls此前运行过
XV6将
cc程序的内核线程的内核寄存器保存在一个context对象中因为要切换到
ls程序的内核线程,那么ls程序现在的状态必然是RUNABLE,表明ls程序之前运行了一半。这同时也意味着:a.
ls程序的用户空间状态已经保存在了对应的trapframe中b.
ls程序的内核线程对应的内核寄存器已经保存在对应的context对象中所以接下来,XV6会恢复
ls程序的内核线程的context对象,也就是恢复内核线程的寄存器。之后
ls会继续在它的内核线程栈上,完成它的中断处理程序恢复
ls程序的trapframe中的用户进程状态,返回到用户空间的ls程序中最后恢复执行
ls
线程切换的核心函数
void swtch(struct context *old, struct context *new)(switch 是C 语言关键字,因此这个函数命名为swtch 来避免冲突):这是用汇编来写的
swtch函数会保存用户进程 P1 对应内核线程的寄存器至context对象。所以目前为止有两类寄存器:
- 用户寄存器存在
trapframe中 - 内核线程的寄存器存在
context中
- 用户寄存器存在
实现很简单,就是把当前
context里面的寄存器保存在以a0(old)为基址的地方,然后从a1(new)里面恢复寄存器的值实际上
swtch函数并不是直接从一个内核线程切换到另一个内核线程。XV6中,一个CPU上运行的内核线程可以直接切换到的是这个CPU对应的调度器线程所以如果我们运行在CPU0,
swtch函数会恢复CPU0的调度器线程保存的寄存器和stack pointer,之后就在调度器线程的context下执行schedulder函数中为什么会跳到scheduler函数呢,调度器线程的 ra 事先保存的

调度器线程的ra被设置为了scheduler函数的入口,从而在swtch返回时通过ra跳到了这里
为什么RISC-V中有32个寄存器,但是swtch函数中只保存并恢复了14个寄存器?
学生回答:因为switch是按照一个普通函数来调用的,对于有些寄存器,swtch函数的调用者默认swtch函数会做修改,所以调用者已经在自己的栈上保存了这些寄存器,当函数返回时,这些寄存器会自动恢复。所以swtch函数里只需要保存Callee Saved Register就行
为什么swtch函数要用汇编来实现,而不是C语言?
Robert教授:C语言中很难与寄存器交互。可以肯定的是C语言中没有方法能更改sp、ra寄存器。所以在普通的C语言中很难完成寄存器的存储和加载,唯一的方法就是在C中嵌套汇编语言。所以我们也可以在C函数中内嵌switch中的指令,但是这跟我们直接定义一个汇编函数是一样的。或者说swtch函数中的操作是在C语言的层级之下,所以并不能使用C语言
swtch函数是线程切换的核心,但是swtch函数中只有保存寄存器,再加载寄存器的操作。线程除了寄存器以外的还有很多其他状态,它有变量,堆中的数据等等,但是所有的这些数据都在内存中,并且会保持不变
我们没有改变线程的任何栈或者堆数据。所以线程切换的过程中,处理器中的寄存器是唯一的不稳定状态,且需要保存并恢复。而所有其他在内存中的数据会保存在内存中不被改变,所以不用特意保存并恢复。我们只是保存并恢复了处理器中的寄存器,因为我们想在新的线程中也使用相同的一组寄存器。
值得注意的是,调用swtch之前,都持有
p->lock这个锁,很疑惑,按照常理来说一般获取锁的线程还要负责释放锁,但是这里是swtch了,把释放锁的工作交给切换的线程,why?因为
p->lock保护进程state和context字段上的不变量,而这些不变量在swtch中执行时不成立- 如果在
swtch期间没有保持p->lock,可能会出现一个问题:在yield将其状态设置为RUNNABLE之后,但在swtch使其停止使用自己的内核栈之前,另一个CPU可能会决定运行该进程(因为他看到这个进程的状态是RUNNABLE)。结果将是两个CPU在同一栈上运行,这是致命的
- 如果在
这也是为什么在 forkret 最开头需要 release 锁,锁都是在这里释放的吗?
考虑调度代码结构的一种方法是,它为每个进程强制维持一个不变量的集合,并在这些不变量不成立时持有
p->lock
void scheduler(void):
通过进程表单找到下一个RUNABLE进程P2,然后swtch到这个找到的进程
先保存自己的寄存器到调度器线程的context对象
找到进程P2之前保存的context,恢复其中的寄存器
因为进程P2在进入RUNABLE状态之前,如刚刚介绍的进程P1一样,必然也调用了swtch函数。所以之前的swtch函数会被恢复,并返回到进程P2所在的系统调用或者中断处理程序中(注,因为P2进程之前调用swtch函数必然在系统调用或者中断处理程序中)。
不论是系统调用也好中断处理程序也好,在从用户空间进入到内核空间时会保存用户寄存器到trapframe对象。所以当内核程序执行完成之后,trapframe中的用户寄存器会被恢复。
最后用户进程P2就恢复运行了。
void sched(void):做一些合理性检查,发现异常则panic,然后swtch到当前CPU的调度器线程
- 检查:想要放弃CPU的进程必须先获得自己的进程锁
p->lock,并释放它持有的任何其他锁,更新自己的状态(p->state) - 并检查这些条件的隐含条件:由于锁被持有,中断应该被禁用
补充
内核线程总是在sched中放弃其CPU,并总是切换到调度程序中的同一位置,而调度程序(几乎)总是切换到以前调用sched的某个内核线程。在两个线程之间进行这种样式化切换的过程有时被称为协程(coroutines),XV6中 sched和scheduler`是彼此的协同程序。
调度器线程——内核线程的一种
- 每一个CPU都有一个完全不同的调度器线程。调度器线程也是一种内核线程,它也有自己的context对象。任何运行在CPU1上的进程,当它决定让出CPU,它都会切换到CPU1对应的调度器线程,并由调度器线程切换到下一个进程。
- 每一个调度器线程都有自己独立的栈。这个栈是在
entry.S设置的调度器线程栈,即调度器线程运行在CPU对应的bootstack上
context保存在哪?(每一个内核线程都有一个context对象)
- 用户线程对应的内核线程:保存在用户进程对应的proc结构体中
- 调度器线程:没有对应的进程和proc结构体,所以调度器线程的context对象保存在cpu结构体中
在XV6的代码中,context对象总是由swtch函数产生,所以context总是保存了内核线程在执行swtch函数时的状态。当我们在恢复一个内核线程时,对于刚恢复的线程所做的第一件事情就是从之前的swtch函数中返回
调度器线程调用了swtch函数,但是我们从swtch函数返回时,实际上是返回到了对于swtch的另一个调用,而不是调度器线程中的调用。我们返回到的是pid为4的进程在很久之前对于switch的调用。这里可能会有点让人困惑,但是这就是线程切换的核心。
xv6线程第一次调用swtch函数
思考一下swtch函数,实际上是从一个线程对于swtch的调用返回到了另一个线程对于swtch的调用(通过保存的ra)。那么线程第一次调用swtch函数时,需要伪造一个“另一个线程”对于switch的调用,是吧?因为也不能通过swtch函数随机跳到其他代码去。
那么特别重要的就是ra,swtch通过这个返回
在创建一个线程时,allocproc会设置好它的pid,trapframe page,user page table,然后是context
1 | static struct proc* |
可以看到 ra 被设置为了 forkret,说明第一次swtch到这个新的线程时都会返回forkret的开头
forkret只会在启动线程的时候以这种看起来奇怪的方式运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18void
forkret(void)
{
static int first = 1;
// Still holding p->lock from scheduler.
release(&myproc()->lock);
if (first) {
// File system initialization must be run in the context of a
// regular process (e.g., because it calls sleep), and thus cannot
// be run from main().
first = 0;
fsinit(ROOTDEV);
}
usertrapret();
}释放调度器之前获取的锁
if(first)是什么意思?
- XV6只能在进程的context下执行文件系统操作,比如等待I/O。所以初始化文件系统需要等到我们有了一个进程才能进行。而这一步是在第一次调用forkret时完成的,所以在forkret中才有了if(first)判断
forkret 其实伪造了我们从usertrapret,使程序看起来像从trap中返回,跳到用户的第一个指令,注意pc需要被设置为0
因为fork拷贝的进程会同时拷贝父进程的程序计数器,所以我们唯一不是通过fork创建进程的场景就是创建第一个进程的时候。这时需要设置程序计数器为0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// Set up first user process.
void
userinit(void)
{
struct proc *p;
p = allocproc();
initproc = p;
// allocate one user page and copy initcode's instructions
// and data into it.
uvmfirst(p->pagetable, initcode, sizeof(initcode));
p->sz = PGSIZE;
// prepare for the very first "return" from kernel to user.
p->trapframe->epc = 0; // user program counter
p->trapframe->sp = PGSIZE; // user stack pointer
...
}可以看到把epc设置为了0
具体示例可以看Lecture 11 - Thread Switching 中文版_哔哩哔哩_bilibili
44分之后