xv6-locks
自旋锁,睡眠锁,死锁,锁排序,锁的粒度
Chapter 6 锁
为什么需要锁?
- 多CPU内核:计算机的多个CPU之间独立执行,如xv6的RISC-V。多个处理器共享物理内存,这种共享增加了一种可能性,即一个CPU读取数据结构,而另一个CPU正在更新它
- 单CPU多线程内核:内核也可能在许多线程之间切换CPU,导致它们的执行交错
以上可能导致数据损坏,单词并发(concurrency)是指由于多处理器并行、线程切换或中断,多个指令流交错的情况。
锁作为并发控制的一种,广泛使用。锁提供了互斥,确保一次只有一个CPU可以持有锁。如果程序员将每个共享数据项关联一个锁,并且代码在使用一个数据项时总是持有相关联的锁,那么该项一次将只被一个CPU使用。在这种情况下,我们说锁保护数据项。
锁的缺点是它会扼杀性能,因为他会串行化并发操作
一个例子:xv6的kfree实现是把一个内存页面添加到空闲链表上,这涉及到一个push操作。考虑这样一个情况,两个CPU同时执行push,如果没有锁,你的push实现可能是这样的
1 | struct element { |
现在两个CPU同时执行了15行,即将执行16行,这会出现错误
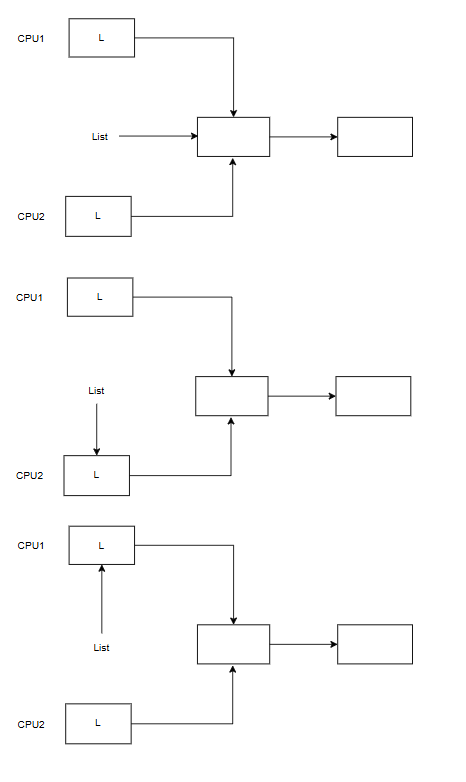
我们假定CPU2先执行16行,CPU1再执行16行,可以看到CPU1的执行会覆盖CPU2的执行,导致我们最后顺着list为头的链表,会找不到CPU2分配的L,这就是竞态条件的例子
竞态条件是指多个进程读写某些共享数据(至少有一个访问是写入)的情况。竞争的结果取决于进程在处理器运行的确切时机以及内存系统如何排序它们的内存操作,这可能会使竞争引起的错误难以复现和调试。例如,在调试push时添加printf语句可能会改变执行的时间,从而使竞争消失。(神奇的内核。。)
那么如何解决这个问题呢,锁来了!在敏感的代码行加一把锁来保护共享数据
1 | void |
acquire和release之间的指令序列通常被称为临界区域(critical section)它们要么会一起执行,要么一条也不会执行
当我们说锁保护数据时,我们实际上是指锁保护适用于数据的某些不变量集合。通常,操作的正确行为取决于操作开始时不变量是否为真。操作可能暂时违反不变量,但必须在完成之前重新建立它们
在链表的例子中,不变量是
list指向列表中的第一个元素,以及每个元素的next字段指向下一个元素。push的实现暂时违反了这个不变量:在第17行,l->next指向list(注:则此时list不再指向列表中的第一个元素,即违反了不变量),但是list还没有指向l(在第18行重新建立)。我们上面检查的竞态条件发生了,因为第二个CPU执行了依赖于列表不变量的代码,而这些代码(暂时)被违反了。正确使用锁可以确保每次只有一个CPU可以对临界区域中的数据结构进行操作,因此当数据结构的不变量不成立时,将没有其他CPU对数据结构执行操作妙!
锁的位置对性能也很重要。例如,在push中把acquire的位置提前也是正确的:将acquire移动到第13行之前完全没问题。但这样对malloc的调用也会被串行化,从而降低了性能
总结:一个非常保守同时也是非常简单的规则:如果两个进程访问了一个共享的数据结构,并且其中一个进程会更新共享的数据结构,那么就需要对于这个共享的数据结构加锁
如何实现锁?
自旋锁spinlock
为什么叫自旋,因为上锁的过程是在一个死循环里面
结构体定义
1 | struct spinlock { |
- 主要关注locked这个字段,为0表示这个锁没有被某个进程持有,为1表示被某个进程持有
aquire
一种可能实现:
1 | void |
- 这段代码还是有问题
- 执行流是指令级别的,而不是C语言代码级别的,因此这样一段代码反汇编之后就容易看出问题,可能造成两个控制流都判断锁没有被占用
- 可能会发生两个CPU同时到达第5行,看到
lk->locked为零,然后都通过执行第6行占有锁。此时就有两个不同的CPU持有锁,从而违反了互斥属性。我们需要的是一种方法,使第5行和第6行作为原子(即不可分割)步骤执行。
- 处理器通常提供实现第5行和第6行的原子版本的指令。RISC-V上是
amoswap r,a:这条指令的会把r的值写入a指向的地址,并且将a这个地址原本指向的值写入r,也就是交换了寄存器r和指定内存地址的值
解决方法:原子操作
__sync_lock_test_and_set:返回值是lk->locked的旧(交换了的)内容
1 | while(__sync_lock_test_and_set(&lk->locked,1) != 0 )//返回值不为0,表示这个锁一直被持有,因此我们自旋等待 |
反汇编
1 | loop: |
为什么要传一个1进去,效果是什么
- 如果原来里面的值是1,上锁,那么和1交换没有改变
- 如果原来里面的值是0,没有上锁,那么和1交换之后就上锁了
相当于一条指令就完成上锁和后面的判断
获取锁后,用于调试,acquire将记录下来获取锁的CPU。lk->cpu字段受锁保护,只能在保持锁时更改
release
与acquire相反:它清除lk->cpu字段,然后释放锁
从概念上讲,release只需要将0分配给lk->locked。
C标准允许编译器用多个存储指令实现赋值,因此对于并发代码,C赋值可能是非原子的。因此release使用执行原子赋值的C库函数__sync_lock_release。
1 | void release(struct spinlock*lk){ |
反汇编大概如下:就是直接把0写进去
1 | s1 = &lk->locked |
睡眠锁
有时候需要长时间保持锁。如果另一个进程想要获取自旋锁,那么长时间保持自旋锁会导致获取进程在自旋时浪费很长时间的CPU。
自旋锁的一个缺点是在自旋等待时不能主动让出CPU,但是我们希望某些持有锁的进程在等待磁盘I/O的时候其他进程可以使用CPU
为什么自旋锁不能主动让出CPU?
- 如果你在持有自旋锁时让出了CPU,然后第二个进程试图获取这个自旋锁,那么就有可能导致死锁
- 在持有锁时让步也违反了在持有自旋锁时中断必须关闭的要求。
因此我们希望有这样一个锁:它在等待获取锁时让出CPU(不自旋),并允许在持有锁时让步(以及中断)
注意sleeplock是进程级别的,spinlock是CPU级别的?
1 | // Long-term locks for processes |
acquiresleep ( kernel/sleeplock.c:22) 在等待时让步CPU
睡眠锁有一个被自旋锁保护的锁定字段,acquiresleep对sleep的调用原子地让出CPU并释放自旋锁。结果是其他线程可以在acquiresleep等待时执行。
限制:
- 因为睡眠锁保持中断使能,所以它们不能用在中断处理程序中
- 因为
acquiresleep可能会让出CPU,所以睡眠锁不能在自旋锁临界区域中使用(尽管自旋锁可以在睡眠锁临界区域中使用) - 因为等待会浪费CPU时间,所以自旋锁最适合短的临界区域;睡眠锁对于冗长的操作效果很好
如何使用锁?
锁的bug有时难以复现,竞争仅仅是可能发生
使用锁的一个困难部分是决定要使用多少锁,以及每个锁应该保护哪些数据和不变量。
有几个基本原则:
- 任何时候可以被一个CPU写入,同时又可以被另一个CPU读写的变量,都应该使用锁来防止两个操作重叠
- 请记住锁保护不变量(invariants):如果一个不变量涉及多个内存位置,通常所有这些位置都需要由一个锁来保护,以确保不变量不被改变。
粗粒度锁
如果并行性不重要,那么可以安排只拥有一个线程,而不用担心锁。一个简单的内核可以在多处理器上做到这一点,方法是拥有一个锁,这个锁必须在进入内核时获得,并在退出内核时释放(尽管如管道读取或wait的系统调用会带来问题)。(一把大锁保平安)
缺点:牺牲了并行性:一次只能有一个CPU运行在内核中。如果内核做一些繁重的计算,使用一组更细粒度的锁的集合会更有效率,这样内核就可以同时在多个处理器上执行。
例子:上面所说的kalloc对应的空闲链表,在不同CPU之间是同一个,所以需要单个锁来保护。改进:可以每个CPU一个空闲列表,每个列表都有自己的锁,然后如果某个CPU不够用了,再从另一个CPU调度
细粒度锁
xv6对每个文件都有一个单独的锁,这样操作不同文件的进程通常可以不需等待彼此的锁而继续进行
xv6中的所有锁。
| 锁 | 描述 |
|---|---|
bcache.lock |
保护块缓冲区缓存项(block buffer cache entries)的分配 |
cons.lock |
串行化对控制台硬件的访问,避免混合输出 |
ftable.lock |
串行化文件表中文件结构体的分配 |
icache.lock |
保护索引结点缓存项(inode cache entries)的分配 |
vdisk_lock |
串行化对磁盘硬件和DMA描述符队列的访问 |
kmem.lock |
串行化内存分配 |
log.lock |
串行化事务日志操作 |
管道的pi->lock |
串行化每个管道的操作 |
pid_lock |
串行化next_pid的增量 |
进程的p->lock |
串行化进程状态的改变 |
tickslock |
串行化时钟计数操作 |
索引结点的 ip->lock |
串行化索引结点及其内容的操作 |
缓冲区的b->lock |
串行化每个块缓冲区的操作 |
我们想要获得更好的性能,那么我们需要有更多的锁,但是这又引入了大量的工作
通常来说,开发的流程是:
- 先以coarse-grained lock(注,也就是大锁)开始。
- 再对程序进行测试,来看一下程序是否能使用多核。
- 如果可以的话,那么工作就结束了,你对于锁的设计足够好了;如果不可以的话,那意味着锁存在竞争,多个进程会尝试获取同一个锁,因此它们将会序列化的执行,性能也上不去,之后你就需要重构程序。
例子:xv6的yield函数
1 | // Give up the CPU for one scheduling round. |
实际上,在锁释放之前,进程的状态会变得不一致,例如,yield将要将进程的状态改为RUNABLE,表明进程并没有在运行,但是实际上这个进程还在运行,代码正在当前进程的内核线程中运行。
所以这里加锁的目的之一就是:即使我们将进程的状态改为了RUNABLE,其他的CPU核的调度器线程也不可能看到进程的状态为RUNABLE并尝试运行它。否则的话,进程就会在两个CPU核上运行了
死锁和锁排序
如果在内核中执行的代码路径必须同时持有数个锁,那么所有代码路径以相同的顺序获取这些锁是很重要的
如果不以相同的顺序获取锁,可能导致死锁:
- 假设xv6中的两个代码路径需要锁A和B,
- 代码路径1按照先A后B的顺序获取锁
- 另一个路径按照先B后A的顺序获取锁
- 假设线程T1执行代码路径1并获取锁A,线程T2执行代码路径2并获取锁B。接下来T1将尝试获取锁B,T2将尝试获取锁A。两个获取都将无限期阻塞,因为在这两种情况下,另一个线程都持有所需的锁,并且不会释放它,直到它的获取返回。
全局锁获取顺序的需求意味着锁实际上是每个函数规范的一部分:调用者必须以一种使锁按照约定顺序被获取的方式调用函数。
多的锁通常意味着更多的死锁可能性
不过在设计一个操作系统的时候,定义一个全局的锁的顺序会有些问题。如果一个模块m1中方法g调用了另一个模块m2中的方法f,那么m1中的方法g需要知道m2的方法f使用了哪些锁。因为如果m2使用了一些锁,那么m1的方法g必须集合f和g中的锁,并形成一个全局的锁的排序。这意味着在m2中的锁必须对m1可见,这样m1才能以恰当的方法调用m2。
但是这样又违背了代码抽象的原则。在完美的情况下,代码抽象要求m1完全不知道m2是如何实现的。但是不幸的是,具体实现中,m2内部的锁需要泄露给m1,这样m1才能完成全局锁排序。所以当你设计一些更大的系统时,锁使得代码的模块化更加的复杂了
没有必要对所有的锁进行一个全局的排序,但是所有的函数需要对共同使用的一些锁进行一个排序。
clockintr定时器中断处理程序在增加ticks(kernel/trap.c:163)的同时内核线程可能在sys_sleep(kernel/sysproc.c:64)中读取ticks。锁tickslock串行化这两个访问。
中断和死锁
假设sys_sleep持有tickslock,并且它的CPU被计时器中断中断。clockintr会尝试获取tickslock,意识到它被持有后等待释放。在这种情况下,tickslock永远不会被释放:只有sys_sleep可以释放它,但是sys_sleep直到clockintr返回前不能继续运行。所以CPU会死锁,任何需要锁的代码也会冻结。
解决办法:如果一个自旋锁被中断处理程序所使用,那么CPU必须保证在启用中断的情况下永远不能持有该锁(也就是你不能在进入中断前拿走别人的锁)
xv6的解决方法是:当CPU获取任何锁时,xv6总是禁用该CPU上的中断。直到release该锁的时候才开启中断。中断仍然可能发生在其他CPU上,此时中断的acquire可以等待线程释放自旋锁;由于中断不在同一CPU上,不会造成死锁。
acquire调用push_off (kernel/spinlock.c:89) 并且release调用pop_off (kernel/spinlock.c:100)来跟踪当前CPU上锁的嵌套级别。当计数达到零时,pop_off恢复最外层临界区域开始时存在的中断使能状态。intr_off和intr_on函数执行RISC-V指令分别用来禁用和启用中断。
严格的在设置lk->locked (kernel/spinlock.c:28)之前让acquire调用push_off是很重要的。如果两者颠倒,会存在一个既持有锁又启用了中断的短暂窗口期,不幸的话定时器中断会使系统死锁。同样,只有在释放锁之后,release才调用pop_off也是很重要的( kernel/spinlock.c:66)。
指令和内存访问顺序
我们自然地会想到程序是按照源代码语句出现的顺序执行的。然而,许多编译器和中央处理器为了获得更高的性能而不按顺序执行代码。
如果一条指令需要许多周期才能完成,中央处理器可能会提前发出指令,这样它就可以与其他指令重叠,避免中央处理器停顿
例如,中央处理器可能会注意到在顺序指令序列A和B中彼此不存在依赖。CPU也许首先启动指令B,或者是因为它的输入先于A的输入准备就绪,或者是为了重叠执行A和B。编译器可以执行类似的重新排序,方法是在源代码中一条语句的指令发出之前,先发出另一条语句的指令。
例如,在push的代码中,如果编译器或CPU将对应于第4行的存储指令移动到第6行release后的某个地方,那将是一场灾难:
1 | l = malloc(sizeof *l); |
如果发生这样的重新排序,将会有一个窗口期,另一个CPU可以获取锁并查看更新后的list,但却看到一个未初始化的list->next。
为了避免这样的重新排序,使用__sync_synchronize()
- 是一个内存障碍:它告诉编译器和CPU不要跨障碍重新排序
load或store指令 - 强制顺序执行