rCore-Blog
2023 秋 rCore 训练营个人存档:二三阶段优秀
二阶段实验总结
lab1
目的就是实现三个信息的统计
status: TaskStatus
- 按照提示直接设置为running
[syscall_times: [u32; MAX_SYSCALL_NUM]
- 第一次尝试直接在sys_task_info来加载,发现好像不行,因为不知道传入的ti: *mut TaskInfo,这个参数到底在哪里被初始化的,而且每个任务都需要有一个syscall_times数组
- 由此我在
TaskControBlock中维护一个pub task_syscall_times: [u32; MAX_SYSCALL_NUM]数组,这样通过全局遍历TASK_MANAGER可以很好的在每次系统调用时更新 - 更新位置在
trap_handler进入syscall之前,读取x17寄存器为syscall id
time: usize
需要得到的是从第一次运行到现在的时间,现在的时间可以通过
get_time_ms直接获得第一次运行开始的时间,需要在应用第一次变成Running态的时候记载,因此我们为每个
1
TaskControBlock
中维护
pub task_start: usize,记录任务第一次开始的时间pub task_flag: bool,标志是否为第一次,如果是就是false,然后我们更新task_start,并且将该变量置为false,保证只记录一次start time
lab2
直接<<12直接这样会报错overflow,但是那个函数确实就是干了这个事情,只是我帮他弄了一把,很奇怪,还是最后用函数了
taskInfo报错,按照群里大佬这样修改,但不知道为什么这样修改
1 | //原 |
疑问
vpn_end计算有问题,len需要/8吗:不需要,因为VA就是取最低39位,不会左移右移啥的- 上取整,如果已经对齐的情况下还会上取整吗:回答,不会的
bug与问题
- 对于判断是否mapped过,只考虑了
find_pte不能为None,没有考虑find_pte存在,但是pte.is_valid()不合法这件事,卡了很久,也不好调试 - MapPermission不好进行零初始化,那么就用match,但是match要解决穷尽匹配,我们先把不合法的删去,然后最后一个_只代表
6的情况 - 对题意理解有问题,在mmap中,我以为如果start和end之间有已经被映射的页,我们还是需要分配len这么长,也就是不error,映射一段不连续的虚拟内存,写了比较复杂,后面才知道直接error
- 这章很难debug,看样子甚至是多线程跑测试,所以花费很多时间
lab3
继承上一章修改
今天上下午一直在移植代码,尝试了git cherry-pick试了很久,重置过去重置过来,问了gpt,看了b站,csdn都无果,就是没有合并,只显示reports文件夹有冲突,主要的os没有,遂还是采用git diff打patch的笨方法,冲突太多了,合并了小一个小时。
修理waitpid
移植好之后,make run确实能跑了,但是随便输一个就报错,说waitpid清除僵尸进程的引用计数有错,本来应该是1,结果是2,多了一个,debug找不出来,println也没看出来在哪里。仔细想想,找了跟Arc有关的所有代码,可以肯定一件事,模板代码一定没问题,那问题就出在我自己移植过来的代码,最后一个个注释排除法,找到了原来是我自己用了一个Arc没有drop,我以为drop了inner的RefMut就可以了,没想到这个也要drop。为啥这个不会自动drop呢?
目前还有usertest卡住的问题,再看看。
spawn
通过注释发现卡住的原因是spawn的实现有问题,重点在维护父子关系,注意drop的位置
- spawn就是新建一个进程而已,不要想着用fork+exec,之前直接调用fork()和exec()会出问题,也不好调试,于是自己仿照fork内容与exec自己实现
stride
stride感觉倒是很简单,根据提示BIG_STRIDE需要大一点,于是把BIG_STRIDE设置为了0x100000,然后每次调度的时候,都要fetch_task,于是在这里找出最小的stride返回,pass的维护在set_piro里面实现,因为prio只会在这里修改
lab4
这章我真的心累了,调试了两天,目前还是有一个神奇的bug,我觉得不是我代码的问题
在ch6_file2里面:我做了如下修改,//后的就是新加入的
1 | let test_str = "Hello, world!"; |
发现在 link(fname, lname0); //此处传入的lname0是0x0,为什么,看运行结果(在open系统调用和link加入了println!打印传入str的地址),部分结果如下
1 | open:path is 0x42cd |
可以看到lname对应的new name在open里面的地址是0x42d4,但是在link里面是0x0,就是这个bug让我以为我的link出错了,改了一整天,后面copy别人的代码也不行,真的心累了。。请教了群里的一位大佬,还没回我,希望能解决…
解决!syscall 陷入时参数写错了,这个是 git cherry pick的时候自动覆盖掉了,很坑爹
自己对于rust的理解还是不够,还是要在实践中多用,但很感谢能通过这个机会锻炼自己~~
三阶段总结
调试技巧:使用用户态 qemu 进行对拍
测例库里编译的测例都是完全符合规范的 RISC-V 可执行程序,所以它当然可以在其他内核上运行。
如果你还记得,在 rCore-Tutorial的 ch0配环境的时候,安装了 qemu-riscv64 和 qemu-system-riscv64。后者用于运行实验,而前者实际上是一个用户态模拟器。换而言之,它可以直接运行用户态的 RISC-V 程序,我们可以直接把测例文件扔给它。
例如在 testcases/ 目录下执行 qemu-riscv64 ./build/hello,就可以获取正确输出(可以打开 testcases/src/hello.c 看看正确输出长什么样)。
同样地,也可以执行 qemu-riscv64 ./build/42。这个用户程序在退出时返回了一个 42,不过没有打印输出。但我们可以在上面的命令之后立即执行
1 | echo $? |
就可以看到返回值 42
$?是一个shell的变量,表示上一条命令的返回值。在这个例子中,具体来说是
qemu的返回值。它执行了我们要求的用户程序,然后把用户程序的返回值作为自己的返回值,推给宿主机。
如此一来,后续我们每次遇到一个新的应用程序,就可以用 qemu-riscv64 进行检查,看看正常的“内核”运行它应该是什么样的,然后来推测我们的内核运行同一个测例时出了什么错。
我们把这种调试方式叫做“对拍”。
lab1
修改hello测例
首先运行hello后,发现输出Incorrect argc,点进hello.c里面查看,发现是argc传入不对,结合实验书测例库里面,对于c语言和rCore的用户栈排布不一样,推测应该是这个原因,造成c语言里面传入的argc不是想要的参数
于是阅读ch7的命令行参数这一章节,了解了sys_exec是如何把命令行参数压入用户栈,以及用户库如何从用户栈上还原命令行参数
那么接下来就是找出C语言规定栈和rCore栈的区别了,为了方便把指导书上栈展示的顺序从低到高改为从高到低
1 | position content size (bytes) |
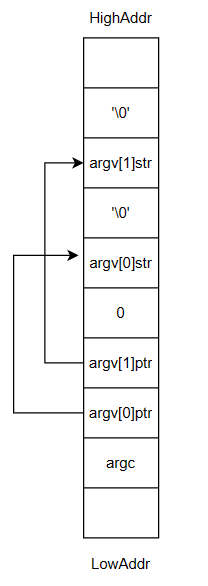
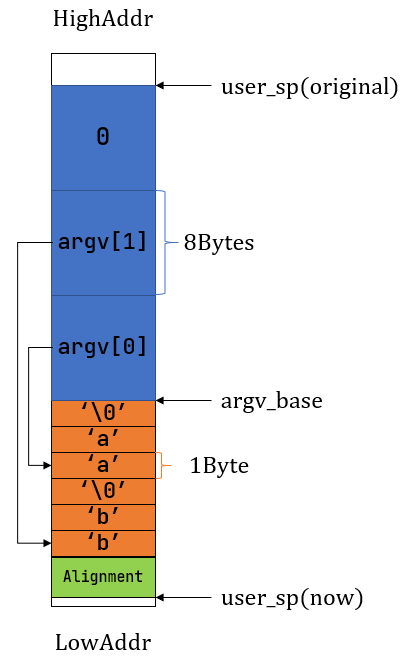
可以发现黄色部分和蓝色部分顺序是反的,因此我们思路就有了,找到方法交换这两部分
修改后代码
1 | //首先预留好所有的位置,从后往前预留,其实顺序无关紧要,减去的总数都是一样的 |
有一个很重要的点是,不要对齐user_sp,如果对齐了user_sp,那么在传入a1的时候,就不能这样赋值user_sp + core::mem::size_of::<usize>(),对齐后user_sp已经不是最初的版本了,会出现错误,一个解决方式是事先保存,不过rCore上面说不对齐对qemu没有影响,我就先不管了。
实验结果
问答题:elf与bin的区别
1 | ch6_file0.elf: ELF 64-bit LSB executable, UCB RISC-V, RVC, double-float ABI, version 1 (SYSV), statically linked, stripped |
ELF 格式执行文件经过 objcopy 工具丢掉所有 ELF header 和符号变为二进制镜像文件bin
elf里面含有不少其他信息,程序头之类的,但是bin里面只有纯数据
如何使用反汇编:
1 | riscv64-linux-musl-objdump <path> -ld > <name>.S |
lab2
编程作业1:跟着教程做
主要是要用引入的mod里的用户栈初始函数来替换lab1写的,具体如下,调用几个引入的mod里的api
1 | let elf = ElfLoader::new(elf_data).unwrap(); |
编程作业2:添加syscall
根据教程,每步出现Unsupported syscall_id: 29这种报错,我们采用以下步骤初步处理
- 在
syscall/mod.rs里添加对应的syscall_id常量 - 查询对应id的syscall,通过此网页
- 重点关注
DESCRIPTION,RETURN VALUE,ERROR,适当取舍实现
通过报错我们依次处理了三个syscall
29 sys_ioctl
尝试直接0返回,但是没有输出hellostd,尝试直接搬过来sys_write,但是失败(不知道怎么实现)
进汇编看一下调用ioctl的时候,传了哪些参数,因为翻看手册对里面写的request参数感觉很模糊,不知道要干嘛
在ecall前,传入的参数为
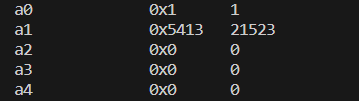
后来发现这个地方直接0返回就行,因为我把writev看成了readv,因此输出hellostd这个活应该是在writev这里干的
66 sys_writev
这里一开始看错了,把66看成了readv,导致全部syscall改完之后,以为唯一需要更改的是ioctl这个,但是无从下手,事实上readv,writev这两个对应的手册就是一样的…
思考过程
发现直接调用sys_write好像不行,报错
1 | xrzr|r~r[kernel] Panicked at src/fs/stdio.rs:55 called `Result::unwrap()` on an `Err` value: Utf8Error { valid_up_to: 0, error_len: Some(1) } |
转回去看手册,writev就是从几个地址写入fd,写入iovcnt次,因此思路就是调用iovcnt次sys_write,但是为了保险起见,我还是没有使用嵌套的系统调用,复制粘贴修改了一下sys_write写到sys_writev中
1 | ssize_t writev(int fd, const struct iovec *iov, int iovcnt); |
去查阅了一下musl源码,全局搜索iovec,得到iovec结构体的定义
1 | STRUCT iovec { void *iov_base; size_t iov_len; }; |
改写到rust中
1 | /os/src/syscall/mod.rs |
代码实现
1 | /// writev syscall |
自己第一次没思考清晰的地方
- 在这个函数里面传入了
Iovec结构体的指针,这是个虚拟地址,需要先得到它的物理地址才能访问这个结构体里面存的东西,对应translated_ref - 结构体内存的是一个虚拟地址和一个usize,因此这个虚拟地址还需要再次翻译才能正确写入,对应
translated_byte_buffer
最终结果
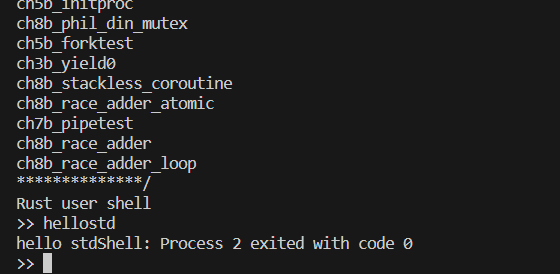
94 sys_exitgroup
退出一个进程的所有线程
尝试直接0返回,成功
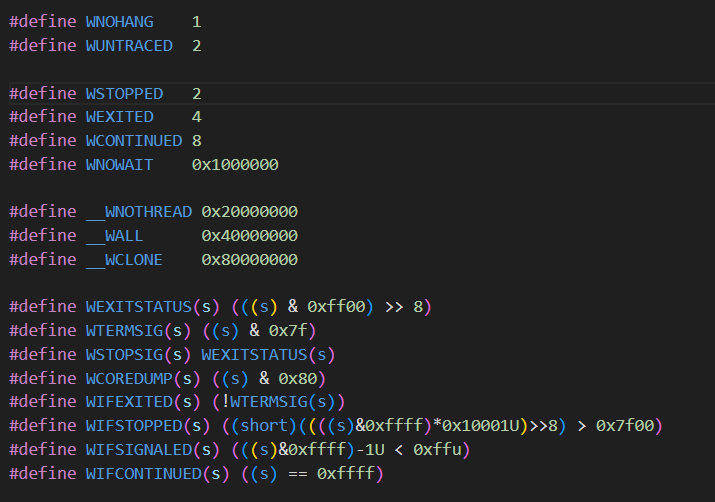
问答作业
options,调用可直接按位或
lab3
思考题
思考题1.1
cargo缓存比如log库的代码在:
1 | /root/.cargo/registry/src/mirrors.ustc.edu.cn-61ef6e0cd06fb9b8/log-0.4.20/src |
思考题1.2:如果忘记 make clean 会发生什么?
不会panic,而是make run成功
思考题2:在部分往届内核及运行指引 一节提到的内核中挑选一个,描述它在默认情况下启动后会执行哪些测例(抑或是直接启动终端)。
选择的Titanix
首先看了下readme,得知make run之后会进入busybox的shell,因此第一个应该就是busybox
测试用例
思考题3.1:为什么要在开头结尾各输出一句,会不会太过重复?(提示:考虑执行出错的情况,或者 sys_exit )
开头的是必须的,可以看到exitgroup每次都是直接退出,没有输出返回值,对比一下图中的两个框

思考题3.2:为什么要结尾还要输出一遍 syscall 的完整参数,只输出返回值行不行?(提示:考虑像 sys_yield 这样的 syscall)
yield用于切换进程,让出当前进程的执行权,如果切换到其他进程,参数是会改变的,因此结尾要再输出一遍完整参数
strace
使用方法:直接把strace加在要运行的命令之前,就能看到执行命令过程中执行的所有syscall
注意执行strace的路径应该要有执行命令的elf或文件
strace 也可以加一些参数,常用的有
-c按种类统计syscall的执行时间、次数和报错次数。注意,“报错”只是代表返回小于 0 的错误码,不代表用户程序出错。例如检查文件是否不存在时也可以用sys_openat,得到ENOENT(没有此文件)的结果属于“报错”,但这就是我们预期的结果。-p <PID>表示指定追踪的进程ID。如果想调试一个大的应用程序,可能会有许多进程共同协作,我们可以指定关心某一个-t输出时间信息;-T显示每次调用的时间-f追踪fork;-F追踪fork和vfork-e [!]value[,value2]指定要追踪的syscall- 如
-e clone,read就是只看sys_clone和sys_read -e \!read表示不看sys_read
- 如
实验3.1 修复busybox mv
首先捋一下教程里面修复ls的过程
- 修改启动侧例,单独分析有问题的
ls的输出 - 在
syscall函数里面,写上error!输出信息(包括:syscall id,args),方便调试 - make run获取错误答案
- 调试往届内核错误,应该找Linux的syscall对拍,使用
strace,采用在本机调试(涉及具体文件操作?) - strace获取“标准答案”
- 对照找不同,可以依据linux文档找syscall定义
实验
首先获取标准答案:
strace busybox mv abc bin/
1 | ... |
make run,题目说是mv的问题,因此只截取了mv片段:
1 | ... |
- 可以看到中间有个
FSTATAT返回了-64,阅读deal_result知道返回值的处理是添加一个-号,因此实际是返回一个64
make run LOG=debug得到一个error:get stat error: ENONET
应该就是fstatat有问题吧
根据fstat的debug信息查看一下调用了哪些函数
1 | [syscall] id = FSTATAT, args = [18446744073709551516, 4128, 1073740160, 0, 4128, 18446744073709551516], entry |
get_stat_in_fs一定返回一个err,全局搜索ENONET定位了错误位置,在此修改即可,注意根据调试信息可以知道get stat error出现的位置,防止混淆(因为有多个get stat error)
依据strace得到正确的返回值应该是-1,但是ENOENT在LinuxError对应的是2呀,根据语义修改为ENOENT
修改后返回值可以对上了,但是mv报错:
1 | mv: can't rename 'abc': Operation not permitted |
翻译一下renameat(2)的内容
1 | int renameat2(int olddirfd, const char *oldpath, |
描述
- 用于重命名文件,如果需要,可以将文件移动到其他目录。对文件创建的硬链接(使用
link(2)创建)不受影响。对于oldpath的打开文件描述符也不受影响。 - 如果
newpath已经存在,它将被原子性地替换,因此在访问newpath时不会找不到文件的情况。但是,可能存在一个时间窗口,其中oldpath和newpath都引用正在被重命名的文件。 - 如果
oldpath和newpath是引用同一文件的现有硬链接,则rename()不执行任何操作,并返回成功状态。 - 如果
newpath存在但由于某种原因操作失败,rename()保证保留newpath的一个实例。 oldpath可以指定一个目录。在这种情况下,newpath要么不存在,要么必须指定为空目录。这个有疑问- 如果
oldpath是符号链接,则重命名该链接;如果newpath是符号链接,则将覆盖该链接。 - 如果
oldpath中给定的路径是相对路径,则它相对于由文件描述符olddirfd引用的目录进行解释(而不是相对于调用进程的当前工作目录,如rename()对于相对路径所做的那样)。如果oldpath是相对路径且olddirfd是特殊值AT_FDCWD,则oldpath相对于调用进程的当前工作目录进行解释
flags
RENAME_EXCHANGE:原子地交换oldpath和newpath。这两个路径必须存在,但可以是不同类型的(例如,一个可能是非空目录,另一个可能是符号链接)。RENAME_NOREPLACE:不要覆盖rename的newpath。如果newpath已经存在,则返回错误。RENAME_NOREPLACE不能与RENAME_EXCHANGE一起使用。RENAME_WHITEOUT(自Linux 3.18起):此操作仅对overlay/union文件系统实现有意义。指定RENAME_WHITEOUT会在重命名的源文件同时创建一个”whiteout”对象。整个操作是原子的,因此如果重命名成功,则”whiteout”也将已创建。”Whiteout”是在union/overlay文件系统结构中具有特殊含义的对象。在这些结构中,存在多个层,只有顶层会被修改。在上层的”whiteout”将有效地隐藏下层的匹配文件,使其看起来好像文件不存在。当重命名存在于下层的文件时,首先将文件复制到上层(如果尚未在上层),然后在上层以读写方式重命名。同时,源文件需要被”whiteout”(以使下层的源文件版本变得不可见)。整个操作需要原子执行。在非union/overlay中,”whiteout”显示为带有{0,0}设备号的字符设备。RENAME_WHITEOUT需要与创建设备节点相同的特权(即CAP_MKNOD能力)。RENAME_WHITEOUT不能与RENAME_EXCHANGE一起使用。RENAME_WHITEOUT需要底层文件系统的支持。支持它的文件系统包括tmpfs(自Linux 3.18起)、ext4(自Linux 3.18起)、XFS(自Linux 4.1起)、f2fs(自Linux 4.2起)、btrfs(自Linux 4.7起)和ubifs(自Linux 4.9起)。
把oldpath复制到newpath这里,如果newpath是一个目录,那么就移动到目录下面,如果newpath不是目录,就重命名(可以执行统一的语义:移到 ./newpath ),最后删除oldpath
看了下rename,如果new存在的话会remove他,代码如下:
1 | let rename_flags = RenameFlags::from_bits(flags as u32).unwrap(); |
flag还没有实现,有时间再补上
得到正确答案:
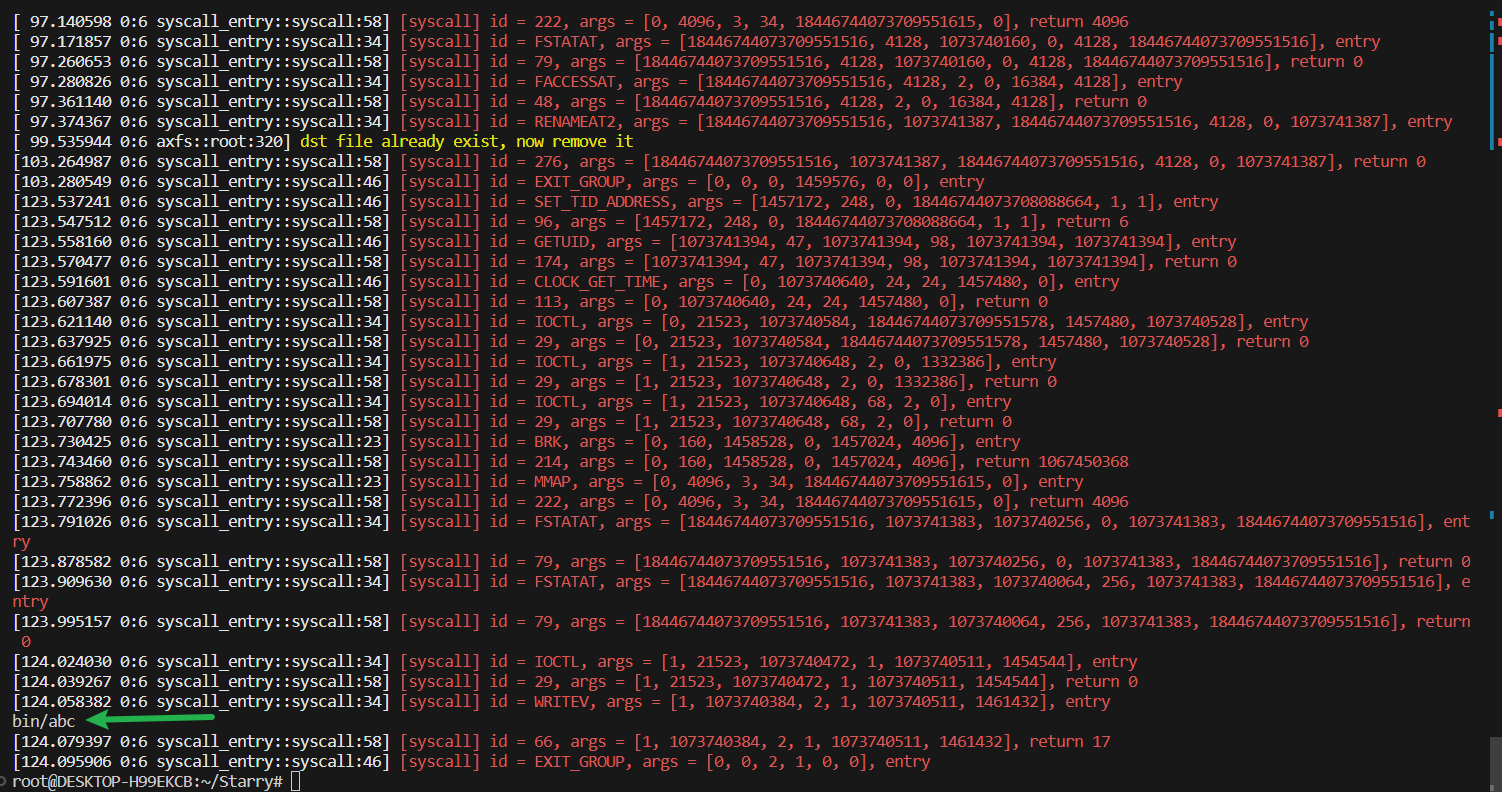
实验3.2
还是老样子首先和本机标准答案对照:
strace busybox mv bin def
1 | ... |
Starry内核:
为了方便调试在renameat2里面加了一句:
1 | error!( |
1 | [syscall] id = FSTATAT, args = [18446744073709551516, 1073741383, 1073740160, 0, 1073741383, 18446744073709551516], entry |
可以看到出问题了,应该是错把dir当成file的错误
与实验3.1的答案对照一下看看
1 | [syscall] id = FSTATAT, args = [18446744073709551516, 4128, 1073740160, 0, 4128, 18446744073709551516], entry |
对比发现deal_with_path会预先处理好new_path,对于上一小节实验给出old_path is /abc,new_path is /bin/abc,而对于这节实验给出old_path is /def,new_path is /bin
由于我error!的位置在处理的最前面,因此,就只有deal_with_path会出现这个问题,进入函数,开始修正
首先做了一个小test,发现不可能存在同名的file和dir
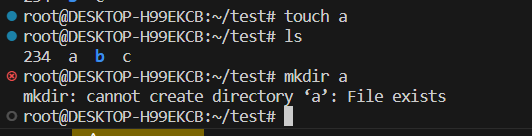
那么是怎么分辨一个没有以
/是dir还是file呢,我的想法是首先获取metadata,利用里面的is_dir和is_file来判断,如果满足是目录而且没有以/结尾,手动给他添上1
2
3
4
5if let Ok(new_data) = metadata(path.as_str()) {
if new_data.is_dir() && !path.ends_with('/') {
path = format!("{}/", path);
}
}可以正确输出
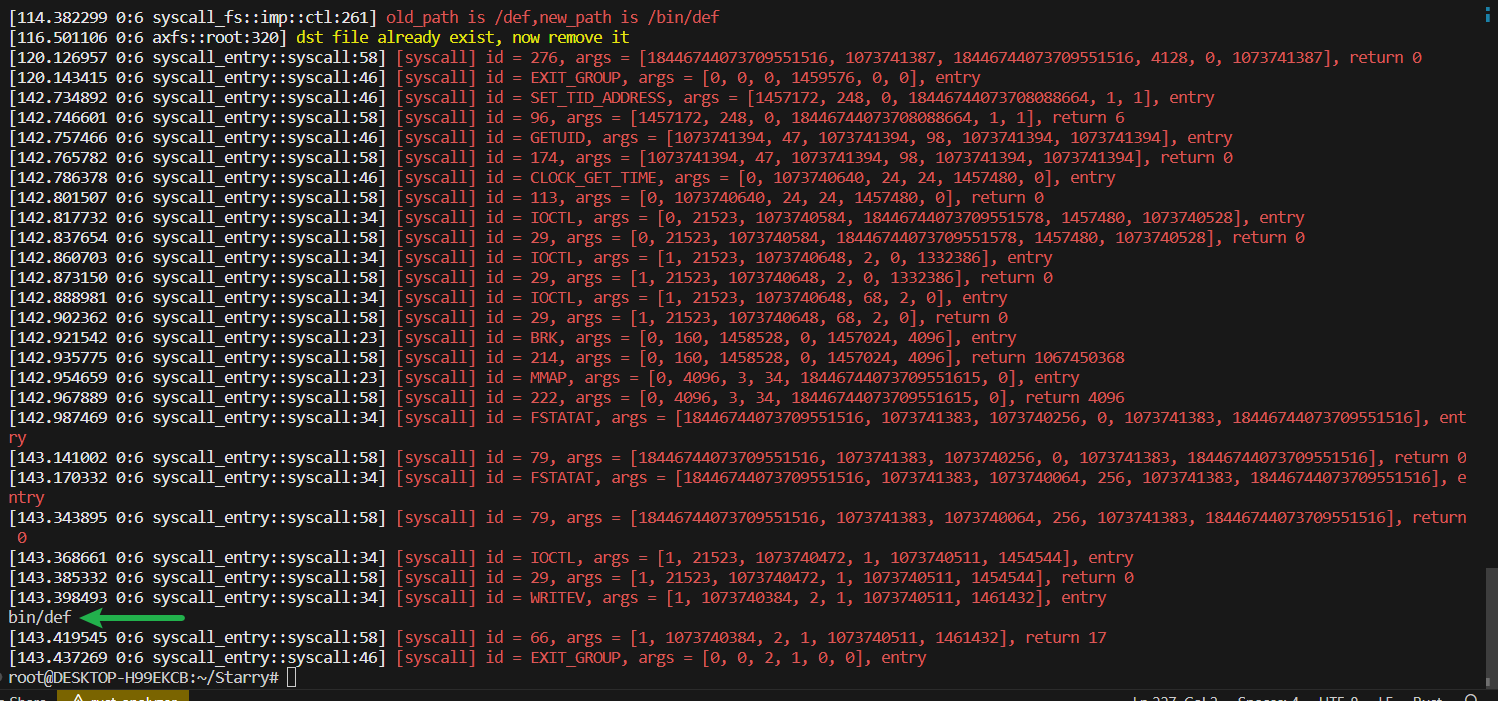
结语
项目二是ArceOs宏内核,当时选项目二的原因是
- 想参加大赛
- 从第二阶段的rCore tutorial学习之后,还有一些疑问,想借这个项目巩固一下,同时跨越从教程到自己写内核的鸿沟
个人觉得收获很大的是调试技巧方面:
gdb:
gdb 不支持跨地址空间的查找。它只知道当前能不能访问某个地址(虚拟地址),不会管现在的页表在哪,所以内核调试时经常会遇到因为地址当前无法访问而打不上断点的情况。这时可分为以下情况处理:
把断点打在内核入口,也即
0x80200000处,然后使用c命令跳过去。之后就可以打大部分内核符号的断点了。把断点打在
mm::init()(页表初始化函数)然后使用c命令跳过去,再用n指令跳过这段流程,就可以打页表中有映射的地址的断点了,例如跳板页TRAMPOLINE。一般来说,如果想打用户程序的断点,先使用
c命令,等待程序运行到user_shell等待输出的时候,再ctrl+C,就可以打用户地址空间的断点了。但缺点是此时无法打内核的断点
总的说来,训练营收获很大,从一开始的只是了解了OS的皮毛,或者说书本上的OS知识,再经过第一阶段,从零开始学习了rust的基础,第二阶段亲自上手体验五个实验,细致地体会OS各种核心的概念,中断、虚拟内存、进程切换、多线程、信号等等,然后第三阶段通过AecOS宏内核的学习,了解到OS大赛所需要的部分知识,我的认知确实有短暂地螺旋上升,很谢谢有这样一个平台能学习OS,感谢。